
ㅅㅇ
딥러닝 _05_DNN_성능개선 본문
플레이데이터 빅데이터캠프 공부 내용 _ 7/14
딥러닝 _05_Deep Neural Networks 모델 성능 개선 기법들
0. 성능을 결정하는 요소
=> 최적화 - 일반화 학습 !! (과적합 줄이기)
특히, 딥러닝에서는 과대적합을 줄일 수 있어야 한다.!!
[ 정확도 와 Loss 중 무엇을 더 중요시 생각해야 할까? ]
= > 성능을 비교할 때는 항상 loss가 기준이다. 정확도는 참고사항
그렇다면, 애초에 Accurancy 와 Loss 의 성능의 결과는 왜 일치 하지 않을까?
- 정확도는 label 을 기준으로 몇 개 중에 몇 개를 맞췄는 지 보는 것이다.
- Loss 는 얼마만큼의 확률로 맞췄는지 보는 것이다.
(그저 맞춘 것 뿐만 아니라, 얼마만큼의 오차를 가지고 있는지까지 보는 것.)
- 틀리더라도 높은 확률로 확실하게 맞춘 모델과 -- (정확도는 낮은데 loss가 높은)
다 맞긴 해도 애매한 확률로 겨우 맞춘 모델을 비교했을 때, -- (정확도는 높은데 loss가 낮은)
=> 더 틀려도 (정확도가 낮아도) 확실하게 높은 확률로 맞춘 (loss가 적은) 모델이 좋다.
1. 최적화와 일반화, 과대적합, 과소적합
1) 최적화(Optimization)
- train data에서 최고의 성능을 얻으려고 모델 파라미터들을 조정하는 과정 (옵티마이저가 한다.)
- 모델이 일반화되기 위한 작업
2) 일반화(Generalization)
- 훈련된 모델이 처음 보는 데이터 ( '학습하지 않은 데이터' )에서 대해 잘 추론할 수 있는 상태.
- ''학습을 통해 일반화된 특징'' 들을 잘 찾은 상태.
3) 과대적합(Overfitting)
- 검증 결과 Train set에 대한 성능은 좋은데 Validation set에 대한 성능은 안좋은 상태로 모델이
학습을 과하게(overfitting)한 상태를 말한다.
- 학습이 과하게 되어 쓸데 없는 패턴을 모두 외워버려 오히려 처음본 데이터에 대한 예측 성능이 떨어진다.
- 우리가 목표한 성능을 떠나서 Train set 과 Val set 의 성능의 차이가 많이 나면 좋지 않다.
- 새로운 데이터 셋을 예측하는 것이 목표인데,
일반화된 특징, 패턴을 찾지 못해 새로운 문제를 풀 수 없다.
- 보통 Train dataset의 크기에 비해 모델이 너무 복잡한 경우 발생한다.
- 보통 과적합이라고 하면 Overfitting을 말한다.
딥러닝의 대부분의 문제는 Overfitting에서 일어난다. (데이터셋에 비해 모델이 복잡)
4) 과소적합(Underfitting)
- 검증 결과 Train set과 Validation set 모두 성능이 안좋은 상태로 모델의 학습이 덜(underfitting)된 상태를 말한다.
- Train dataset의 크기에 비해 모델이 너무 단순한 해서 데이터에 대한 특징들을 다 찾지 못한 상태이다.
- train 과 val 성능의 차이가 크든, 작든
내가 학습으로 사용한 데이터 셋으로 예측 해도 성능이 떨어진 것
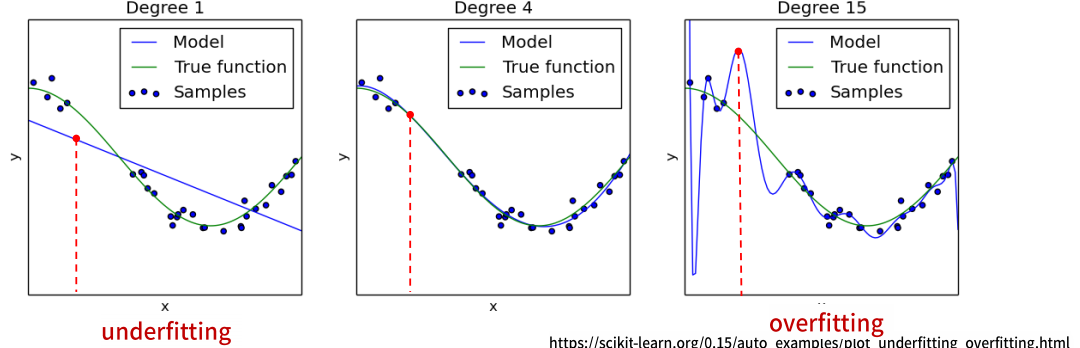

2. 딥러닝에서의 과적합 문제 - Epoch 과 과적합
- 데이터셋을 여러번 반복 학습을 하게 되면 '초반에는' train, validation 성능이 모두 개선된다.
그러나 학습이 계속 반복되면
train 의 성능은 계속 좋아지지만
어느시점 부터는 Overfitting이 발생하여 validation 의 성능은 나빠진다.
- Epoch을 반복하는 것은 같은 데이터셋을 반복적으로 학습하는 것이기 때문에
적절한 Epoch수를 넘어가면 Overfitting이 발생한다.
==> Validation set의 성능이 나빠지기 전의 반복횟수를 모델의 최적의 Epoch으로 선택한다.
3. 과적합 개선
3.1 과소적합 (Underfitting) 개선
1) 모델의 복잡도를 높인다.
- 모델 네트워크의 크기를 키운다.
- Layer나 Unit 개수를 늘린다.
2) Epoch (또는 Step) 수를 늘린다.
- Train/Validation의 성능이 계속 좋아지는 상태에서 끝난 경우, 더 학습을 시킨다.
3.2 과대적합(Overfitting) 개선
= > 과대적합을 방지하기 위한 규제 방식은 모두 모델을 간단하게 만드는 방법들이다.
1) 더 많은 data를 수집
- 모델이 복잡해도 학습 시킬 데이터가 충분히 많으면 괜찮다.
- 일반적으로 데이터를 늘리는데는 시간과 돈이 많이 든다.
- 단, 이미지의 경우, 기존 데이터의 크기를 줄인다거나 회전 시키기, generator 사용 등 으로
가짜 데이터를 만들어 어느정도 늘릴 수 있다. (train set 에만 적용하며, val, test 에는 적용하지 않는다.)
=> Image Augmentation
(음성, 이미지 데이터는 가짜 데이터를 만들기 쉬운 편)
2) 모델의 복잡도를 낮춰 단순한 모델을 만든다.
- 네트워크 모델의 크기를 작게 만든다.
- 모델의 학습을 규제하는 기법을 적용한다.
3) Epoch(또는 step) 수를 줄인다.
- Validation의 성능 지표가 가장 좋았던 Epoch 까지만 학습시킨다.
4. 성능 개선 : DNN 모델 크기 변경으로
- 모델의 layer나 unit 수가 많을 수록 복잡한 모델이 된다.
- Overfitting일 경우 모델을 간단하게 만들고
Underfitting일 경우 모델을 크게 만든다.
== > Layer의 수, 각 layer의 unit 수를 조정 !!
큰 모델에서 시작하여 layer나 unit 수를 줄여가며
validation loss의 감소 추세를 관찰한다. (또는 반대로)
1) 데이터에 비해 작은 모델의 특징
- Train/Validation 성능 개선의 속도가 느리다. (성능이 오르는 기울기가 작다.)
- 반복횟수가 충분하지 않으면 학습이 덜된 상태에서 중단될 수 있다.
- Underfitting이 발생할 가능성이 크다.
2) 데이터에 비해 큰 모델의 특징
- Validation 이 성능이 학습 초반부터 나빠진다.
- Train에 대한 성능은 초반부터 빠르게 개선된다.
- Overfitting 발생할 가능성이 크다.
크기로만 과대적합을 완전히 해결할 수 없다. 그래서 이와 관련해 여러 기법이 연구되었다.
Dropout Layer 추가 방법, Batch Normalization (배치정규화) 방법
이렇게, 두 가지를 배우는데, 이를 하나씩 넣을 수도 있고 둘 다 넣어 처리할 수 도 있다.
어떠한 처리로 성능개선(overfitting 해결)을 해주는 layer 들을 dense layer 사이, 사이에 넣어준다.
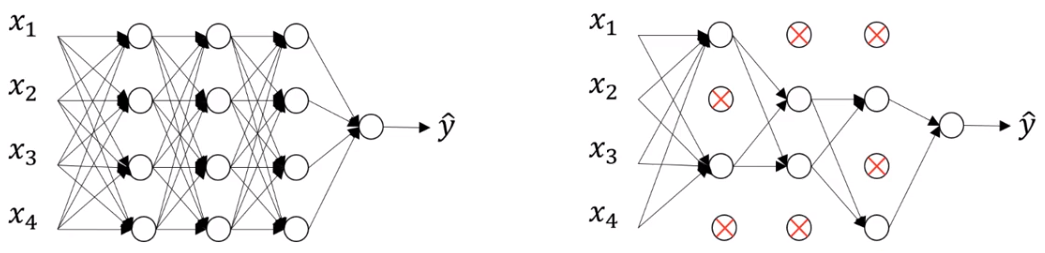
5. Dropout Layer 추가를 통한 Overfitting 규제
: Neural network의 Overfitting을 방지하기 위한 규제(regularization) 기법
- Overfitting의 이유는 모델이 너무 복잡하기 때문이다.
- 너무 복잡한 모델은
학습시 Train dataset으로 부터 관련이 없는 패턴까지 너무 많은 특징을 찾기 때문에 일반성이 떨어지게 된다.
== > network를 만들 때 모든 unit 가 아닌, 일부에서 학습 되도록한다.
1) Dropout Node
: 학습시 일부 Unit(노드)들을 Random하게 빼고 학습한다. 이때 빠지는 노드들을 Dropout Node라고 한다.
= > 선택된 노드들의 weight들을 모두 0으로 학습시킨다. 이 노드들은 최적화 대상에서 빠진다.
2) Dropout rate
- Dropout이 적용되는 Layer에서 Dropout Node의 비율로 보통 0.2~0.5 를 지정한다.
- 너무 크게 지정하면 underfitting이 발생한다.
- 매 Step 마다 Dropout Node들은 random하게 바뀐다. (drop 된게 다음 step 에선 할 수 있고)
3) 효과
: Dropout은 overfitting의 원인인 co-adaptation 현상을 감소/방지하는 효과가 있다.
- co-adaptation 현상이란
- 학습시 생기는 오차를 줄이기 위해 네트워크 내의 모든 Node들의 모든!! 파라미터들이 업데이트 된다.
즉, 발생한 오차에 대해 모든 파라미터가 공동책임으로 업데이트 되는 것이다.
- 그러나, 특정 node 에서만의 문제일 수도 있다.
그렇다면, 이 처리는 적절한 값에 도달한 node 또한 업데이트 시켜
쓸데 없는 패턴까지 학습시키게 만든다.
- 각 Node들의 역할이 나눠지지 못하고 공동화되며
그로 인해 결국, 쓸데 없는 패턴까지 학습하게 되고 이는 overfitting의 원인이 된다.
- 이때, Dropout을 사용하게 되면 학습시 마다 Node들을 학습에서 제외하므로
이러한 co-adaptation 현상을 줄여 줄 수 있다.
- (어떤 애들이 적절한 값에 도달했는지 모르니 학습이 되는 동안 step 단위로 랜덤하게 dropout 한다.)
- Step마다 다른 network를 학습시키는 형태가 되어 앙상블(ensemble) 효과가 있다.
4) 적용
- Dropout은 학습시에만 적용하고 검증, 테스트, 새로운 데이터 추론시에는 적용되지 않는다.
'AI_STUDY > 딥러닝' 카테고리의 다른 글
| 딥러닝_04_tfdata 파이프라인 (0) | 2022.07.14 |
|---|---|
| 딥러닝 _03_2_DNN (Deep Neural Network) 신경망 구조 _ 최적화 (0) | 2022.07.13 |
| 딥러닝 _03_1_DNN (Deep Neural Network) 신경망 구조 (0) | 2022.07.13 |
| 딥러닝 _02_첫번째 딥러닝- MLP 구현 (0) | 2022.07.12 |
| 딥러닝 _ 01_ 개요 및 Tensorflow 설치 (0) | 2022.07.11 |


