
ㅅㅇ
딥러닝 _02_첫번째 딥러닝- MLP 구현 본문
플레이데이터 빅데이터캠프 공부 내용 _ 7/11
딥러닝 _02_첫번째 딥러닝- MLP 구현
MLP(Multi Layer Perceptron) - 가장 기본적인 딥러닝모델의 구조
- dense layer 로만 이뤄진 모델 구조
1. Keras 개발 Process
1. 입력 텐서(X)와 출력 텐서(y)로 이뤄진 훈련 데이터를 정의
2. 입력과 출력을 연결하는 Layer(층)으로 이뤄진 네트워크(모델) 구조를 을 정의
(딥러닝은 머신러닝과 달리 모델 구조는 우리가 설정해야 한다.)
- Sequential 방식: 순서대로 쌓아올린 네트워크로 이뤄진 모델을 생성하는 방식
- Functional API 방식: 다양한 구조의 네트워크로 이뤄진 모델을 생성하는 방식
- Subclass 방식: 네트워크를 정의하는 클래스를 구현.
3. 모델 Compile(컴파일) - 모델을 학습할 수 있는 상태로 만들어준다.
- 모델이 Train(학습) 할때
사용할 손실함수(Loss Function), 최적화기법(Optimizer), 학습과정을 모니터링할 평가지표(Metrics)를 설정
- Compile : 실행할 수 있는 상태 (학습할 수 있는 상태) 로 만들어 주는 것. (기계어로 바꾸는 의미 아님.)
4. Training(학습/훈련)
- Train dataset을 이용해 모델을 Train 시킨다.
2. 딥러닝 대표 예제 데이터 셋 - MNIST 이미지 분류
- MNIST(Modified National Institute of Standards and Technology) database
- 흑백 손글씨 숫자 0-9까지 10개의 범주로 구분해놓은 데이터셋
- 하나의 이미지는 28 * 28 pixel 의 크기
- 6만개의 Train 이미지와 1만개의 Test 이미지로 구성됨.
# 이 데이터 셋으로 딥러닝 분석을 할 것이다.
3. Keras 개발 예제 - MNIST 이미지 분류
3.1 데이터 로드 및 확인
(1) import
- tensorflow 별칭 : tf
import numpy as np # 넘파이
import tensorflow as tf # 텐서플로우 - 별칭 : tf
from tensorflow import keras # keras
(2) MNIST dataset Loading
- 데이터를 (train 이미지 X - 라벨 y), (test 이미지 X - 라벨 y) 로 데이터 나눠서 들고 오기.
(train_image, train_label), (test_image, test_label) = keras.datasets.mnist.load_data()
# import 로 해도 됨. 뭘로 하든 상관없음.
from tensorflow.keras.mnist import load.data
(3) 데이터셋 type 확인 & shape 확인
- type : numpy 배열
type(train_image), type(train_label)(numpy.ndarray, numpy.ndarray)- 각 input data의 shape == > 중요. 데이터 로드 후 항상 확인해야하는 부분.
(데이터개수, 특성의 형태)
(데이터개수, height, width) - 데이터의 갯수, 데이터(이미지) 하나의 행, 열. (색에 대한 없음 - > 흑백)
(60000, 28, 28) : 28x28 (28행, 28열) 사이즈의 흑백(grayscale) 이미지 60000 장
print(train_image.shape, test_image.shape)(60000, 28, 28) (10000, 28, 28)
- 각 label data의 shape
print(train_label.shape, test_label.shape)(60000,) (10000,)
(4) Input 데이터(이미지) 확인 - 시각화( plt.imshow() )
- 0 ~ 19 index 의 데이터 확인 (20장의 이미지)
- 배경 : black (0), 숫자글씨 : white (255)
import matplotlib.pyplot as plt
plt.figure(figsize=(15, 5))
# 20장의 이미지와 label을 확인
N = 20
for i in range(N):
plt.subplot(2, int(N/2), i+1) # 두 줄로 보기
plt.imshow(train_image[i], cmap='gray') # train_image의 i번째 이미지를 출력 - grayscale의 경우 cmap 을 gray로 지정.
plt.title(str(train_label[i]), fontsize=20) # subplot(axes)의 제목을 label로 설정.
# plt.axis('off') # 축을 그리지 않는다.
plt.tight_layout()
plt.show()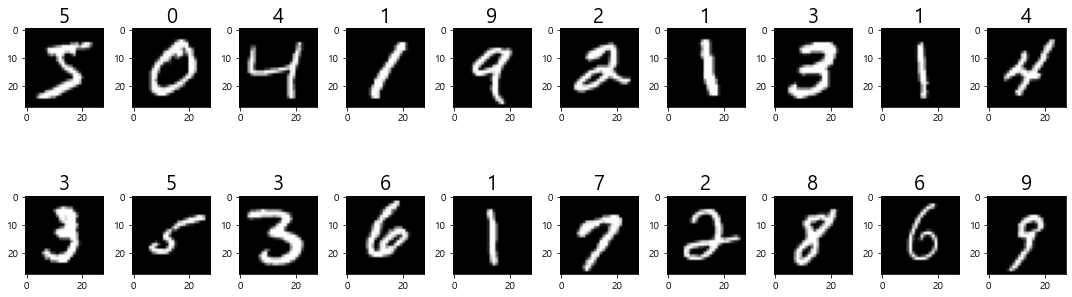
(5) lnput 데이터 확인
train_image[0] # 0번째 데이터
3.2 네트워크 (모델) 구현 및 구조 확인
(1) 네트워크 (모델) 구현
- Network : 전체 모델 구조 를 뜻한다.
- Sequential(순차) 방식으로 모델 생성 : model = keras.Sequential()
- 모델에 layer들을 추가 : model.add(레이어 객체)
- layer : 모델이 추론하는 각각의 단계를 의미
=> Input(학습/추론 할 데이터를 넣어주는 단계), Hidde(추론과정을 담당), Output(추론결과를 출력) Layer 로 구성된다.
1 Input Layer 추가
2 Hidden Layer 들을 추가
- art : 모델 네트워크 만드는 것 (내 데이터에 맞게 모델 구조를 만들어 성능에 영향을 주는 작업)
- 정해진 규칙이 있는게 아니라 내가 만드는 작업
3 Output Layer 추가
- 마지막에 추가된 layer는 output layer 이다.
- input layer : 입력받아,
=> HIDDEN 단계 - layer 단계에서 해야할 일을 하고 출력 내보내고, 다음 layer 입력으로 들어가 일하고 ...
= >마지막 최종 출력 : 출력 내보냄.
- 이전 layer 의 출력이 현재 일할 layer의 입력이 되는 것이다.
# Sequential(순차) 방식으로 모델 생성
model = keras.Sequential()
# 1. Input Layer 추가
model.add(keras.layers.InputLayer((28,28)))
# 2. Hidden Layer 들을 추가
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(256, activation='relu')) # Fully Connected Layer # unit 256 (LR 256- 추론하는애가 256개)
model.add(keras.layers.Dense(128, activation='relu'))
# 3. Output Layer 추가
model.add(keras.layers.Dense(10, activation='softmax'))
(2) 모델의 구조를 확인 (Text로 리턴)
- Output Shape : 해당 layer 처리 후 결과 output 의 shape 를 말해줌.
- flatten 의 out 으로 1차원 배열 (None, 784) 이 나와 dense 의 입력으로 들어간다.
- 데이터의 갯수는 모르기에 none 이다.
- Param : 학습할 대상 갯수 (업데이트 해야할 파라미터 개수. 구조그림에서 선의 갯수 )
model.summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 784) 0
dense (Dense) (None, 256) 200960
dense_1 (Dense) (None, 128) 32896
dense_2 (Dense) (None, 10) 1290
=================================================================
Total params: 235,146
Trainable params: 235,146
Non-trainable params: 0
_________________________________________________________________
(3) 모델의 구조를 확인 (graphviz 이용해 시각화)
# pip install pydot pydotplus graphviz 설치 필요.
from tensorflow.keras.utils import plot_model
plot_model(model, to_file='model_shapes.png', show_shapes=True)
3.3 컴파일 단계 (학습에 필요한 기능을 추가)
- 정의된 네트워크 모델에 학습을 위한 추가 설정을 되어야 컴파일(학습이 가능한 상태)이 가능하다.
- Optimizer (필수) : 최적화 알고리즘
- 손실함수 (필수)
- 평가지표
model.compile(optimizer='adam', # 최적화 함수 : Adam 알고리즘
loss='categorical_crossentropy', # cross entropy
metrics=['accuracy']) # 추가 평가지표 - 정확도
3.4 데이터 준비 - 전처리
- X (Input Data Image) : float32 로 변환하고 0 ~ 1 사이의 값으로 정규화
- 0 ~ 255 = > 0 ~ 1 = > 기존값/255
# minmaxscale 할 필요 없음. ( 데이터 모두 max 값 255 로 동일하기에)
- y (Output Data) 0 ~ 9 : one hot encoding 처리
- Label이 다중분류(Multi class classification)일 경우 One Hot Encoding 한다.
- Keras의 onehot encoding 처리 함수
- tensorflow.keras.utils.to_categorical()
- 일반적인 8 bit 정수표현 : signed int 최상위비트가 부호 비트. -128 ~ 127
- 색농도 0 ~ 255표현 : 음수필요 없음. unsigned int
print(np.min(train_image), np.max(train_image), train_image.dtype, sep=', ')0, 255, uint8
(1) input image(X)를 정규화.
X_train = train_image.astype(np.float32) # 타입 변환: unit8 -> float32
X_train /= 255.0 # X_train= X_train/255.0
X_test = test_image.astype(np.float32)
X_test /= 255.0
print(np.min(X_train), np.max(X_test), X_train.dtype, sep=', ')0.0, 1.0, float32
(2) label (y) 를 one hot encoding
- 모델이 각 클래스 별 확률이 출력되도록 정의 되었기 때문에
y_train = keras.utils.to_categorical(train_label)
y_test = keras.utils.to_categorical(test_label)
print(train_label.shape, test_label.shape) # 변환 전
print(y_train.shape, y_test.shape) # 변환 후(60000,) (10000,)
(60000, 10) (10000, 10)
y_train[:5]array([[0., 0., 0., 0., 0., 1., 0., 0., 0., 0.],
[1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 1., 0., 0., 0., 0., 0.],
[0., 1., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.]], dtype=float32)
3.5 학습 (fit) 및 History 확인
- model.fit()
- 모델 학습 메소드.
- 학습과정의 Log를 History 객체로 반환한다.
- History : train 시 에폭별 평가지표값들을 모아서 제공.
(1) 학습 (fit)
epochs : 전체 train dataset 을 몇 번 반복해서 학습시킬지 정의
(데이터를 여러번 봐야할 필요가 있다. 몇 백 몇 천 줄 수 도 있음. )
== > 1 epoch (단위개념) : 한 번 학습
batch_size : Train dataset 을 학습시키는 단위로 한번에 지정한 개수를 정의
100 개의 데이터 씩 끊어서 학습시킨다.
== > batch-size를 한번 학습한 것을 1 step(단위)
validation_split : train/validation 분리 - val data set 의 비율을 정의
- train set 의 30%(0.3)를 validation set으로 사용
- 문제집(train set) 에 문제가 42000 개
- epochs = 10 : 42000 개 문제를 10 번 풀어라.
- batch_size = 100 : 42000 개의 문제를 100 문제를 단위로 나눠 풀고 정답확인해라. = > 420 step
(100 문제 풀고 정답확인하고 다음 100문제 풀고 정답확인하고 ... 백개의 단위로 문제를 푼다.)
hist = model.fit(X_train, y_train, # input: X_train output : y_train
epochs=10, # 전체 train dataset 을 몇 번 반복해서 학습시킬지 정의.
batch_size=100, # Train dataset 을 학습시키는 단위로 한번에 지정한 개수(100)의 데이터 씩 끊어서 학습
validation_split=0.3 # train/validation 분리 - train set 의 30%(0.3)를 validation set으로 사용
)Epoch 1/10
420/420 [==============================] - 4s 8ms/step - loss: 0.3048 - accuracy: 0.9122 - val_loss: 0.1568 - val_accuracy: 0.9543
Epoch 2/10
420/420 [==============================] - 4s 9ms/step - loss: 0.1157 - accuracy: 0.9655 - val_loss: 0.1154 - val_accuracy: 0.9662
Epoch 3/10
420/420 [==============================] - 3s 7ms/step - loss: 0.0732 - accuracy: 0.9778 - val_loss: 0.1116 - val_accuracy: 0.9663
Epoch 4/10
420/420 [==============================] - 3s 8ms/step - loss: 0.0496 - accuracy: 0.9847 - val_loss: 0.1051 - val_accuracy: 0.9689
Epoch 5/10
420/420 [==============================] - 3s 8ms/step - loss: 0.0348 - accuracy: 0.9894 - val_loss: 0.1031 - val_accuracy: 0.9706
Epoch 6/10
420/420 [==============================] - 3s 8ms/step - loss: 0.0265 - accuracy: 0.9918 - val_loss: 0.1053 - val_accuracy: 0.9718
Epoch 7/10
420/420 [==============================] - 4s 9ms/step - loss: 0.0220 - accuracy: 0.9930 - val_loss: 0.1330 - val_accuracy: 0.9660
Epoch 8/10
420/420 [==============================] - 4s 10ms/step - loss: 0.0176 - accuracy: 0.9945 - val_loss: 0.1086 - val_accuracy: 0.9727
Epoch 9/10
420/420 [==============================] - 3s 8ms/step - loss: 0.0148 - accuracy: 0.9954 - val_loss: 0.1116 - val_accuracy: 0.9726
Epoch 10/10
420/420 [==============================] - 3s 8ms/step - loss: 0.0134 - accuracy: 0.9957 - val_loss: 0.1036 - val_accuracy: 0.9756
- train 70 % 가지고 학습하고 train 과 val set 으로 검증을 한다.
= > train set 데이터 42000 개가 있다.
- banch_size = 100
= > 42000 개 데이터를 100 씩 => 420 step 의 과정을 거친다. (100개씩 420 step 한 게 1 epoch)
= > epochs = 10 => 이걸 10번
[출력 설명]
Epoch 1/10 # 현재 학습중인 epoch/ 전체 epoch수
420/420 [==============================] - 4s 8ms/step - loss: 0.3048 - accuracy: 0.9122 - val_loss: 0.1568 - val_accuracy: 0.9543
# 현재 학습중인 step/전체 step 수 # 1epoch 걸린시간:4s 1step 학습에 걸린시간: 8ms
# - train 오차 loss - accuracy - validation 오차(loss) - validation 정확도
(원래 기본 loss 나오고 아까 추가 평가지표 정확도 추가해서)
- epoch 별 성능을 보면, train 은 여러번 학습을 할수록 좋아진다.
test은 좋아지다가 안 좋아짐 = > 모델이 복잡해짐. overfitting
(2) history 확인 및 시각화
위와 같이 모델이 학습을 끝내면
epoch 별 train 오차loss - accuracy - validation 오차(loss) - validation 정확도 를 반환하는데,
epoch 별 history를 시각화하여 보기 위해 이를 hist 변수에 담아준다.
hist.history - {key 성능이름 : epoch 별 성능변화(loss, accuracy)} dict 형식으로 반환
print(type(hist))
print(type(hist.history))
hist.history<class 'keras.callbacks.History'>
<class 'dict'>
{'loss': [0.300797700881958,
0.11193343251943588,
0.07239670306444168,
0.048918649554252625,
0.0363864041864872,
0.02820790559053421,
0.021542903035879135,
0.015045295469462872,
0.011798908933997154,
0.017987487837672234],
'accuracy': [0.9140238165855408,
0.9668095111846924,
0.9782381057739258,
0.9855476021766663,
0.9883809685707092,
0.9912857413291931,
0.9931666851043701,
0.9955475926399231,
0.9963333606719971,
0.9936904907226562],
'val_loss': [0.14970698952674866,
0.1195853129029274,
0.11769795417785645,
0.09895452111959457,
0.10371357202529907,
0.09293486177921295,
0.1014929711818695,
0.11051476746797562,
0.11349636316299438,
0.10624457895755768],
'val_accuracy': [0.9559444189071655,
0.9640555381774902,
0.9626111388206482,
0.9716110825538635,
0.9708333611488342,
0.9731666445732117,
0.9737777709960938,
0.9726666808128357,
0.9733333587646484,
0.9735000133514404]}
- graph
- loss 오차 - 작을수록 좋은 것.
- accuracy 정확도 - 클수록 좋은 것.
= > 3 epoch 5 epoch 에서 성능 좋음.
import matplotlib.pyplot as plt
plt.figure(figsize=(7,10))
plt.subplot(2,1,1)
plt.plot(range(1,11), hist.history['loss'], label='Train Loss')
plt.plot(range(1,11), hist.history['val_loss'], label="Validation Loss")
plt.title("Loss per Epoch", fontsize=20)
plt.legend()
plt.subplot(2,1,2)
plt.plot(range(1,11), hist.history['accuracy'], label='Train Accuracy')
plt.plot(range(1,11), hist.history['val_accuracy'], label='Validation Accuracy')
plt.title("Accuracy per Epoch", fontsize=20)
plt.legend()
plt.tight_layout()
plt.show()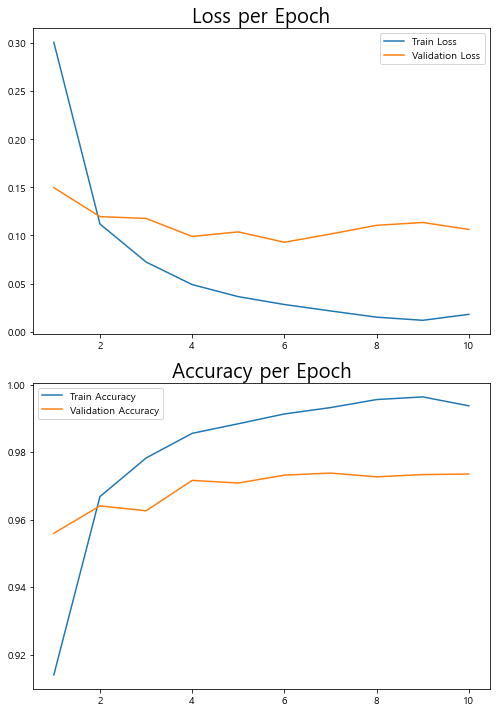
3.6 데이터 셋 평가 = > 최종평가
model.evaluate(X,y)
test_loss, test_acc = model.evaluate(X_test, y_test)313/313 [==============================] - 2s 5ms/step - loss: 0.0840 - accuracy: 0.9801
print(test_loss, test_acc)0.0839601531624794 0.9800999760627747
3.7 새로운 데이터 추론
- 새로운 데이터를 추론하기 전에
학습데이터에 했던 전처리과정을 새로운 데이터 셋에 동일하게 적용 한 뒤 추론한다.
(1) 추론 메소드
- predict() - 회귀이든 분류이든 해당 함수 사용
1) 분류: 각 클래스 별 확률 반환
2) 회귀: 최종 예측 결과
- 분류문제일때 predict() 결과에서 class label 출력하고자 한다면?
모델 출력값을 후처리해서 최종 예측 label 을 확인한다.
1) 이진 분류(binary classification)
- `numpy.where(model.predict(x) > 0.5, 1, 0).astype("int32")`
2) 다중클래스 분류(multi-class classification)
- `numpy.argmax(model.predict(x), axis=1)`
(2) 새로운 데이터 셋 추론 예시
- input image(X) 에 필요한 전처리 : 28x28, float32, 0 ~ 1 정규화, 검은색바탕에 흰 글씨
- X_test 의 처음 5개 데이터를 이용해 새로운 데이터라 하고 추론
= > X_test 는 test_image 를 전처리한 데이터셋(unit8 ->float32 변환, 0 ~ 1 사이로 정규화)
= > 전처리 해줄 필요 없음.
new_image = X_test[:5] # 28x28 이미지 5개
new_image.shape(5, 28, 28)
- predict(예측할 데이터의 Feature) == > (데이터개수, Feature shape) 을 반환
X_test (5,28,28) == > result (5,10) : 5개 이미지에 대해 0~9 사이의 값으로 예측한다.
(onehotencoding = > 10개의 열)
result = model.predict(new_image)
result.shape1/1 [==============================] - 0s 361ms/step
(5, 10)result[0]array([1.9226378e-09, 1.5068100e-08, 1.8938231e-07, 2.4677180e-05,
1.1303006e-14, 3.4873035e-12, 1.2096423e-13, 9.9997413e-01,
7.7752998e-11, 9.2615835e-07], dtype=float32)(3) 예측 결과 (각 class 별 확률) 을 통해 label 을 확인
- 가장 높은 확률이 있는 index 를 받아야 한다.
= > (5, 10) 에서 수평 방향으로 10개 중에 제일 큰 것.
=> axis = - 1 :마지막 축 기준으로 max 값을 가진 index 를 조회 (5,10) 마지막 축은 1번축
# 가장 높은 확률
print(np.max(result[0]))
# 가장 높은 확률이 있는 index
np.argmax(result, axis=-1)
- label 확인
result_label = np.argmax(result, axis=-1)
result_labelarray([7, 2, 1, 0, 4], dtype=int64)
- 시각화 .imshow()
idx = 0
plt.imshow(test_image[idx], cmap='gray')
plt.title(f'{test_label[idx]} : {result_label[idx]}')
plt.show()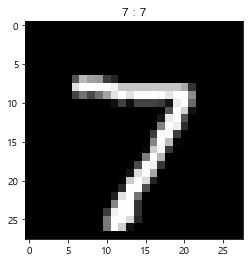
'AI_STUDY > 딥러닝' 카테고리의 다른 글
| 딥러닝 _05_DNN_성능개선 (0) | 2022.07.25 |
|---|---|
| 딥러닝_04_tfdata 파이프라인 (0) | 2022.07.14 |
| 딥러닝 _03_2_DNN (Deep Neural Network) 신경망 구조 _ 최적화 (0) | 2022.07.13 |
| 딥러닝 _03_1_DNN (Deep Neural Network) 신경망 구조 (0) | 2022.07.13 |
| 딥러닝 _ 01_ 개요 및 Tensorflow 설치 (0) | 2022.07.11 |


