
ㅅㅇ
Pandas _ 02-2 DataFrame 주요 메소드, 속성 본문
Pandas_01-2 Series 주요 메소드, 속성
1. 주요 기본 메소드, 속성

(1) .T : 행/열을 바꾼다.
(1,1), (2,2) .... 은 안 바뀌고 (1,0)은 (0,1) , (0,1)은 (1,0) ...
grade.T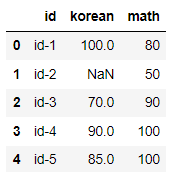

- 테이블프레임 조회 시 컬럼이 너무 많을 때 이를 행으로 바꿔서 보거나 한다.
(2) .head() : 상위 .tail() : 하위 (기본값:5)
# 기본값 - 상위 5개
movie_df.head(7)
# 기본값 - 하위 5개
movie_df.tail(2)
(3) .shape : axis(순번의 방향)별 데이터 수
튜플로 반환 => (행수, 열수) : 0축, 1축
movie_df.shape
(4916, 28)
(4) .size : 원소의 갯수
= 행*열 (보통, 크기를 말할 때 4916 X 28 이라고 말함.)
movie_df.size, 4916*28 # (137648, 137648)
(5) .info() : DateFrame의 (행, 열에 대한) 정보를 반환
grade.info()```
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5 entries, 0 to 4 ======> 행 정보 RangeIndex : Index명 정보, 5 entries (행수), 0 to 4 (index 명)
Data columns (total 3 columns): ======> 컬럼 정보
# Column Non-Null Count Dtype
(이름) (컬럼별원소수) (컬럼병 데이터 타입)
--- ------ -------------- -----
0 id 5 non-null object (문자열 타입)
1 korean 4 non-null float64
2 math 5 non-null int64
dtypes: float64(1), int64(1), object(1) ======> 각 타입별 컬럼개수 : 타입(컬럼개수)
memory usage: 248.0+ bytes ======> 메모리 공간 (불필요한 공간이면 줄여야 한다.)
Non-Null Count =====> 결측치 확인이 가능!
```
(6) DF[바꿀 컬럼명].astype('바꿀타입') : 컬럼의 타입 변환
만약, 한 컴럼의 최대값 max 이 349000 최소값 min 0 이라면,
int64 메모리 공간을 쓸 필요가 없다. 그렇다면 메모리 절약을 위해 타입을 변환해보자.
movie_facebook_likes 를 int64 => int32 (값하나를 64bit -> 32bit)
- 변환후 다시 변수에 담아줘야 한다.
df2['movie_facebook_likes'] = df2['movie_facebook_likes'].astype('int32')2. 기술통계량 메소드
1차원 자료구조 series의 기술통계량은 전체 데이터에 대한 기술통계량 값 반환
2차원 자료구조 DataFrame의 기술통계량은
기본적으로! def
( axis = 0 )
=> 컬럼별 기술통계량을 반환. => series로 반환
-> series이니 인덱싱, 슬라이싱 조회로 하나씩 뽑을 수 있다.
-> 조회한 값에 대해 또 메소드 처리 할 수 있다.
그러나,
모든 데이터가 수치데이터인 경우 등 행 별로 기술통계량이 구해질 때가 혹은 구할 때가 있다.
( axis = 1 ) : 행 별 기술 통계량을 반환.
ex) df.sum(axis = 1)

(1) DF.max() : '컬럼별' 기술통계량 가장 큰 값을 반환.
- 문자열은 사전식 알파벳
- 컬럼명을 Index로 가진 series로 반환
-> series이니 인덱싱, 슬라이싱 조회로 '특정 컬럼의 기술 통계량' 을 뽑을 수 있다.
grade.max()
id id-5
korean 100.0
math 100
dtype: object
grade.max()['korean']
100.0
(2) DF.sum() : 컬럼별 합계
- 컬럼명을 Index로 가진 series로 반환
grade.sum()
(3) DF.mean() : 컬럼별 평균
- 컬럼명을 Index로 가진 series로 반환
- 문자열 object type을 제외하고 통계치를 계산할 수 있는 컬럼만 반환.
(4) DF.describe()
- 각 컬럼명 별로 요약통계량을 반환한다 = > 기술통계량명을 index, 컬러명명이 col => DF 로 반환
- 기본값 : 수치형(int, float) 타입의 컬럼의 요약 통계량을 반환.
grade.describe()
- 컬럼의 타입을 지정하면 그 타입의 컬럼에 대한 요약 통계량을 반환.
컬럼의 타입 지정 방법 : 매개변수로 include=['데이터 타입'] -- 아래에서 배움
grade.describe(include=['object'])
- 지정한 타입의 컬럼을 제외하고 요약 통계량 반환.
grade.describe(exclude=['float64'])
- 요약본을 볼 때 흔히 컬럼수가 너무 많다면 이때 T 를 사용한다. 행과 열을 바꿔서 조회.
movie_df.describe().T
** 경고 메시지 무시
보통, 경고메시지를 무시해도 되는 업무에서 분석 전 맨 앞에 작성해준다.
# 경고 메시지 무시
import warnings
warnings.filterwarnings(action='ignore')
'AI_STUDY > Pandas' 카테고리의 다른 글
| Pandas _ 02-4 DataFrame 접근 _ 컬럼/행의 값 조회 및 변경 (0) | 2022.06.08 |
|---|---|
| Pandas _ 02-3 DataFrame 접근 _ 컬럼/행 조회 및 변경 (0) | 2022.06.08 |
| Pandas _ 02-1 DataFrame 개요 & 생성 및 저장 (0) | 2022.06.07 |
| Pandas _ 01-2 Series 주요 메소드 , 속성 (0) | 2022.06.07 |
| Pandas _ 01-1 pandas 개요, Series 생성 및 접근 (0) | 2022.06.03 |



