
ㅅㅇ
Pandas _ 01-2 Series 주요 메소드 , 속성 본문
Pandas_01-2 Series 주요 메소드, 속성
- Date(series 객체)를 처리(연산자,메소드)
- Series객체의 속성과 메소드
1. 주요 기본 메소드, 속성
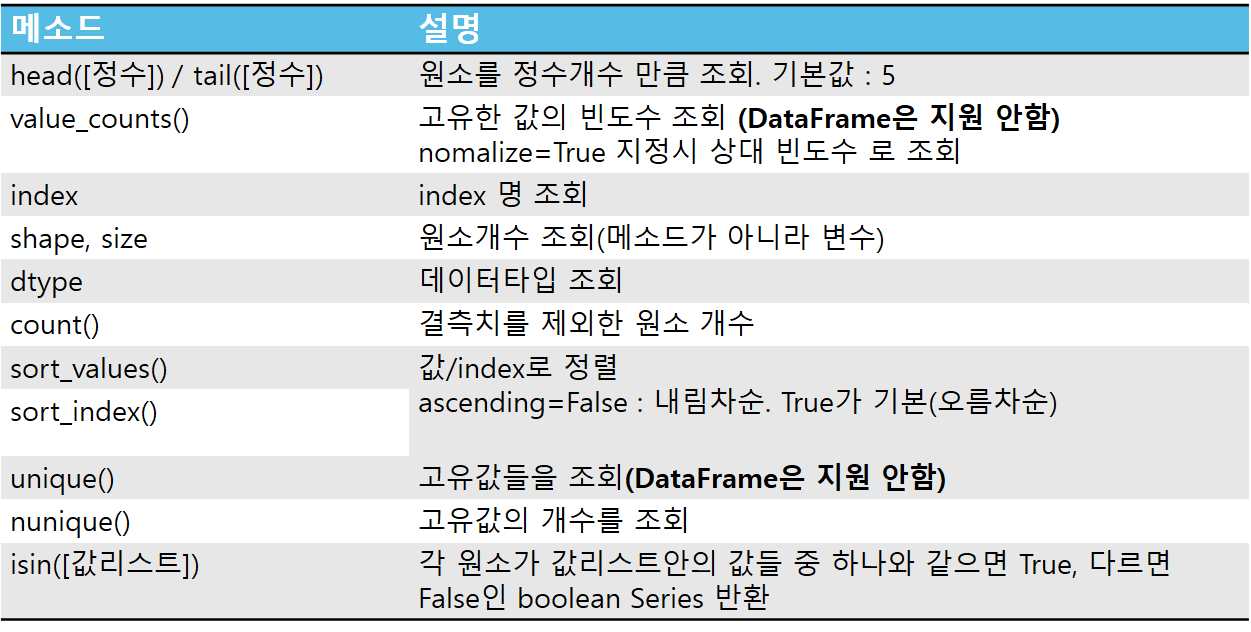

(1) .head(), .tail() - 앞 뒤의 일부 데이터만 조회
- default 값 = 앞, 뒤 5개의 원소
- 괄호 안 값 = 개수를 명시
- tail() 한다고 뒤 원소부터 정렬해서 반환하는 것 아님. (9,10,11,12,13 이런 식으로 순서대로)
s1.head() # 앞의 5개 원소
s1.head(2) # 개수를 명시
s1.tail() # 뒤의 5개 원소
s1.tail(7) # 뒤의 7새 원소
(2) .value_counts() - 각각의 범주값들이 몇 개씩 있는 지 조회
- 범주형 : 정해진 범위의 값들로 구성된 타입. 분류 시 사용
- 자주 쓰인다.
- 반환 타입이 series : 각각의 범주값이 인덱스명. 갯수가 값
s2 = pd.Series(['A', 'A', 'AB', 'O', 'B', 'AB', 'B', 'O','A'])
r = s2.value_counts()
A 3
AB 2
O 2
B 2
dtype: int64- 조회 결과가 Series로 반환되기에 이렇게 특정 원소에 대한 count 조회도 할 수 있다.
r['A'], r['AB']
(3, 2)- 비율 조회 (상대빈도수로 조회)
s2.value_counts(normalize=True)
A 0.333333
AB 0.222222
O 0.222222
B 0.222222
dtype: float64
(3) .shape .size .count() - 원소 개수 조회
- .shape : 차원 별 (순서의 방향. 축 axis ) 별로 원소가 몇 개씩 구성되어있는 지 반환 (튜플로 반환)
배열의 형태를 알려줌. (메소드 아니고 변수)
데이터프레임 조회에서는 행수(0번축), 열수(1번축) 을 먼저 파악하라.
- .size : 결측치를 포함한 총 원소의 개수를 반환 (메소드 아니고 변수)
- .count() : 결측치를 제외한 원소 개수 (메소드)
s2 = pd.Series(['A', 'A', 'AB', 'O', 'B', 'AB', 'B', 'O','A'])
print(s2.shape) # 이걸 더 많이씀 # 지금은 1차원이니 size 값과 같게 나옴.
print(s2.size) # 전체 원소의 개수
(9,)
9
(4) .unique() - 고유값 반환
.numique() - 고유값의 개수 반환
- 범주형 변수를 구성하는 고유값들을 반환. 그러나, value count하면 되서 많이 쓰진 않음.
s2.unique() # 범주형 변수를 구성하는 고유값들을 반환.
array(['A', 'AB', 'O', 'B'], dtype=object)
s2.nunique() # 고유값의 개수
4
(5) .isin([ ]) - [ ] 의 값인 index는 True, 아니면 False를 반환
s2.isin(['A','AB'])- 조회 결과 bool tpye이 series로 반환되기 때문에
인덱스로 넣어서 원하는 값만 불러오도록 사용할 수 있다.
s2[s2.isin(['A','AB'])]
0 A
1 A
2 AB
5 AB
8 A
dtype: object
2. 기술 통계 메소드
- 기술 통계치 count ~ quantile - 결측치와 관련된 isnull~ astpye

2.1 기술 통계량
: 데이터셋의 데이터들의 특징을 하나의 숫자(결과)로 요약한 것.
- 기술의 의미 : 통계량을 쓰는 것. technical 기술 아님.
(1) 평균 .mean()
- 전체 데이터들의 합계를 총 개수로 나눈 통계량(산술평균)
- 전체 데이터셋의 데이터들은 평균값 근처에 분포되어 데이터셋의 대표값으로 사용한다.
- 이상치(너무 크거나 작은 값)의 영향을 많이 받는다. 전체를 표현하는 대표값의 효능이 떨어짐. 이때 중앙값을 쓴다.

(2) 중앙값 .median()
- 분포된 값들을 작은값부터 순서대로 나열(오름차순)한 뒤 그 중앙에 위치한 값
- 이상치에 영향을 받지 않아 평균대신 집단의 대표값으로 사용한다.
ex) 평균과 중앙값
- 중앙값 조회에서 만약 원수의 갯수가 짝수일 때 중앙값은 ? 중간 두 개의 평균값이 반환
- 평균과 중앙값을 조회에서
만약, 두 값이 차이가 많이 나면
극단적으로 크거나 작은 값 이상치가 있다는 의미
# s4, s5는 10000이 있고 없고 차이이다.
s4 = pd.Series([10,5,7,10,20,30,13,21,10000,7,14])
s5 = pd.Series([10,5,7,10,20,30,13,21,7,14])
# 1 평균 계산 - 이상치의 영향으로 평균의 차이가 크다.
s4.mean(), s5.mean() # (921.5454545454545, 13.7)
# 2 중앙값 : 정렬한 후 중간에 있는 값
s4.median() # 중앙값 13.0
# 2 중앙값 - 만약 원수의 갯수가 짝수일 때 중앙값은? 중간 두 개의 평균값이 반환
s5.median() # 11.5
# 평균과 중앙값을 조회
# 만약, 값이 차이가 많이 나면 극단적으로 크거나 작은 값 이상치가 있다는 의미
s4.mean(), s4.median() # (921.5454545454545, 13.0)
(3) 표준편차 .std() /분산 .var()
- 값들이 흩어져있는 상태(분포)를 추정하는 통계량으로
분포된 값들이 평균에서부터 얼마나 떨어져 있는지를 나타내는 통계량.
- 편차(Deviation) : 각 데이터가 평균으로 부터 얼마나 차이가 있는지 ( = 평균 − 각 데이터)
- 분산 : 편차 제곱의 합을 총 개수로 나눈 값

- 표준편차 : 분산의 제곱근
분산은 원래 값에 제곱을 했으므로 다시 원래 단위로 계산한 값.
(편차의 평균을 그냥 내면 0. 그래서 제곱해서 평균(분산)내서 루트 씌워주면 -> 표준편차)

# 분산
print(s4.var())
# 표준편차
print(s4.std())
(4) 최빈값 .mode()
: 데이터 셋에서 가장 많이 있는 값.
- Series로 반환
- 범주형 타입의 대표값으로 많이 쓰인다.
# 최빈값 - 빈도수가 가장 많은 원소(값)
s6 = pd.Series(['A', 'A', 'AB', 'O', 'B', 'AB', 'B', 'O','A', 'O'])
s6.mode() # Series로 반환
# 동일한 갯수로 있다면 둘 다 나옴.
0 A
1 O
dtype: object
(5) 분위수 .quantile()
: 데이터의 크기 순서에 따른 위치값
- 데이터셋을 크기순으로 정렬한뒤 N등분했을 때(동일한 크기. 원소 갯수가 같아야 함.) 특정 위치에서의 값 (단면)
- N등분한 특정위치의 값들 통해 전체 데이터셋을 분포를 파악한다.
- 대표적인 분위수 : 4분위, 10분위 많이씀 // 100분위(100개로 나눈)
- 연속형 타입(값이 실수(정수)로 구성된 변수)의 변수에 사용
- 데이터의 분포를 파악할 때 사용
- 이상치 중 극단값들을 찾을 때 사용 (4분위수 IQR)


- IQR(Interquartile Range) : 중앙의 50 %
=> 이상치 계산할 때 씀
ex ) 분위수 계산 ( 연속형 타입(값이 실수(정수)로 구성된 변수)의 변수에 사용 )
- q: 분위의 비율값을 0~1 사이 실수로 설정.
- default q = [0.5] => 중앙값 median
# 분위수 계산
s5.quantile() # default q = [0.5] => 중앙값
s5.quantile(q=[0.5])- 4분위 : q = 0.25 0.5 0.75
s5.quantile(q=[0.25,0.5,0.75])
0.25 7.75
0.50 11.50
0.75 18.50
dtype: float64- 10분위 : q = 0.1, 0.2 ... 0.9
# for문 이용
s5.quantile(q =[ x/10 for x in range(1,10)])
0.1 6.8
0.2 7.0
0.3 9.1
0.4 10.0
0.5 11.5
0.6 13.4
0.7 15.8
0.8 20.2
0.9 21.9
dtype: float64
(6) 최대값 .max() 최소값 .min()
print(s4.max(), s4.min())
(7) 합계 .sum()
s4.sum()
(8) .descirbe() : 여러 기술통계량을 series묶어서 반환
- 숫자(정수, 실수) 타입의 원소를 가진 Series의 기술통계량은?
s4.describe()
count 11.000000
mean 921.545455
std 3010.991908
min 5.000000
25% 8.500000
50% 13.000000
75% 20.500000
max 10000.000000
dtype: float64
- 범주형(문자열 타입(판다스에서는 object 타입이라고 함))의 원소를 가진 Series의 기술통계량은?
s6.describe()
# unique : 고유값의 갯수
# top : 최빈값
# freq : 최빈값의 갯수
count 10
unique 4
top A
freq 3
dtype: object## count(), mean(), std(), max() .... 등 기술 통계함수는 NoN(결측치)는 제외하고 계산한다. 이를 기억하자.
** size는 결측치 상관없이 총 원소 개수 반환
3. 결측치 (Missing Value, Not Available)
1) 결측치를 확인하고
2) 결측치를 처리해야 한다.
- 결측치 처리 : 1) 결측치 제거
2) 결측치를 다른 값으로 바꾸거나
- 판다스에서 결측치 (직접 넣어줄 때 다음과 같은 값을 넣음)
: None, numpy.nan, numpy.NAN
s6[[0,5]] = np.nan # index 0 과 5에 NaN 결측치 삽입.
s6.isna().sum() # 2 반환 => 결측치 2개- 데이터값 중 결측치가 있다면 series의 타입이 float 이다.

3.1 결측치 확인
- 방법 1 Numpy
- np.isnan(배열) : 배열에 nan이 있니? -> 원소별로 체크
import numpy as np
import pandas as pd
s1 = pd.Series([10, 5, 30, None, 100, np.nan, 120, 90, np.NAN])
np.isnan(s1)
# false : 값, True : 결측치 => 원소별로체크
0 False
1 False
2 False
3 True
4 False
5 True
6 False
7 False
8 True
dtype: bool
- 방법2 Series일 때
- Series객체.isnull() , Series객체.isna() -> 결측치 : ture, 결측치아닌값 : False // 결측치 이니?
- Series객체.notnull() , Series객체.notna() -> 결측치 : False, 결측치아닌값 : True // 결측치 아니니?
# series 함수
s1.isnull()
s1.notnull()
- 방법2 DataFrame일 때
- DataFrame객체.isnull(), DataFrame객체.isna()
- DataFrame객체.notnull(), DataFrame객체.notna()
- 결측치 개수 확인하고 싶을 때 (많이 쓰임.)
sum() 계산 - True : 1 False : 0 해서 계산한다.
=> bool 값을 가진 Series.sum() => True의 개수 => nan의 갯수
s1.isnull().sum() # 3
s1.notnull().sum() # NA 가 아닌 값의 개수
# 이건 s1.count() 하면 되서 안 쓰고 위에 결측치 갯수 세는 건 많이 씀.
3.2 결측치 처리
** 머신러닝에서 결측치가 있으면 이 데이터를 사용할 수 없다.
그래서 이 결측치를 처리 해결해줘야 한다. - > 없애거나, 다른 값으로 대체
가장 가능성이 높은 값으로 대체를 한다. -> 데이터의 대표값들 중으로.
** 사실 기본적으로 drop하는 게 좋다.
평균, 중앙값, 최빈값이 그나마 가능성이 높지만, 그게 실제 값이 아니다.
틀린 확률이 높아져 예측을 방해.
series에서는 제거 하는 게 맞지만, dataframe에서는 제거를 못할 경우가 있다.
(1) 제거 : dropna()
s1.dropna() # default 원본 안 바뀜
s_copy.dropna(inplace=True) # 원본 바뀜(2)다른값으로 대체 : fillna()
- 보통, 연속형(실수) 경우에는 평균이나 중앙값으로 대체한다.
s_copy2.fillna(round(s_copy2.mean(),2)) # 평균 # default 원본 안 바뀜.
s_copy2.fillna(s_copy2.median(), inplace= True) # 중앙값 # 원본 바뀜.- 보통, 범주형 경우에는 최빈값으로 대체한다.
# 현재 최빈값 두 개 . mode() 조회결과는 시리즈. 둘 중 하나 바꿀 값으로 인덱스 적으면 됨.
s6.mode()
s6.fillna(s6.mode()[0])
- 판다스 seires와 dataframe 의 원소를 변경(추가, 수정, 삭제) 하는 함수나 메소드 대부분은
=> 원본을 변경하지 않고 변경된 결과를 새로운 객체에 담아 반환한다.
s1.dropna()
s1
0 10.0
1 5.0
2 30.0
3 NaN
4 100.0
5 NaN
6 120.0
7 90.0
8 NaN
dtype: float64# 그래서 이렇게 변수에 담아서 써야함.
s2 = s1.dropna()
s2
0 10.0
1 5.0
2 30.0
4 100.0
6 120.0
7 90.0
dtype: float64
=> 원본을 변경하려는 경우에는 inplace = True argument 를 설정한다.
# 복사본의 원본 s_copy 를 바꾼다.
s_copy.dropna(inplace=True)
s_copy
0 10.0
1 5.0
2 30.0
4 100.0
6 120.0
7 90.0
dtype: float644. 값 정렬 메소드
(1) Serise.sort_index()
- index 명을 기준으로 정렬
(2) Serise.sort_values()
- 값을 기준으로 정렬
- 공통매개변수
- ascending = True (기본값) -> 오름차순, False - 내림차순
- inplace = False(기본값) -> 정렬결과를 새로운 series에 담아서 반환. 원본은 그대로, True : 원본을 정렬.
- 오름차순이든 내림차순이든 결측치는 제일 마지막에 정렬된다.
# index 명을 기준으로 정렬 - 오름차순 # 원본 안 바뀜.
s2.sort_index()
# index 명을 기준으로 정렬 - 내림차순 # 원본 안 바뀜.
s2.sort_index(ascending=False)
# 값을 기준으로 정렬 - 오름차순 # 원본 안 바뀜.
s2.sort_values()
# 값을 기준으로 정렬 - 내림차순 # 원본 안 바뀜.
s2.sort_values(ascending=False)
# 값을 기준으로 정렬 - 오름차순 # 원본 정렬
s2.sort_values(inplace=True)
5. 벡터화 (연산)
- Elements - wise 연산
- Numpy 배열(ndarray)과 마찬가지로 Series 객체과 연산을 하면 Series 내의 원소 별 연산을 한다.
# Series와 상수 간의 연산
s2 = pd.Series([10,5,22,100,4,7,90,23], index=list('eakrschq'))
s2 + 10
s 14
a 15
c 17
e 20
k 32
q 33
h 100
r 110
dtype: int64
- 결측치를 연산하면 결측치
s1 = pd.Series([10, 5, 30, None, 100, np.nan, 120, 90, np.NAN])
s1 + 10
0 20.0
1 15.0
2 40.0
3 NaN
4 110.0
5 NaN
6 130.0
7 100.0
8 NaN
dtype: float64
- 결측치를 비교 연산을 하면 => False 반환
index 3, 5, 8 : NaN
s1 < 50
0 True
1 True
2 True
3 False
4 False
5 False
6 False
7 False
8 False
dtype: bool
- Series 간의 연산 같은 index 명끼리 연산 (순번이 아니라, 인덱스 명으로.)
s10 = pd.Series([1,2,3])
s20 = pd.Series([10,20,30])
s10 + s20
0 11
1 22
2 33
dtype: int64s20 > s10
# s20[0] > s10[0]
# s20[1] > s10[1]
# s20[2] > s10[2]
0 True
1 True
2 True
dtype: bool
- 이때, 인덱스명이 다르다면??
+, - , * , % ...연산 -> 계산이 안된다. NaN 반환
비교 연산 -> 계산 안된다. ValueError
s10 = pd.Series([1,2,3])
s30 = pd.Series([100,200,300], index=['가','나','다'])
s10 + s30
0 NaN
1 NaN
2 NaN
가 NaN
나 NaN
다 NaN
dtype: float64
s10 > s30 # => 에러 발생
- index의 갯수 즉, 원소의 갯수가 다르다면?
계산 : 인덱스명이 같은 것까지만 계산하고 남는 건 결측치로
비교 연산 : ValueError
s10 = pd.Series([1,2,3])
s40 = pd.Series([1,2,3,4,5])
s10 + s40
0 2.0
1 4.0
2 6.0
3 NaN
4 NaN
dtype: float64
s10 > s40 # 에러'AI_STUDY > Pandas' 카테고리의 다른 글
| Pandas _ 02-4 DataFrame 접근 _ 컬럼/행의 값 조회 및 변경 (0) | 2022.06.08 |
|---|---|
| Pandas _ 02-3 DataFrame 접근 _ 컬럼/행 조회 및 변경 (0) | 2022.06.08 |
| Pandas _ 02-2 DataFrame 주요 메소드, 속성 (0) | 2022.06.08 |
| Pandas _ 02-1 DataFrame 개요 & 생성 및 저장 (0) | 2022.06.07 |
| Pandas _ 01-1 pandas 개요, Series 생성 및 접근 (0) | 2022.06.03 |



