
ㅅㅇ
Pandas _ 02-1 DataFrame 개요 & 생성 및 저장 본문
Pandas _ 02-1 DataFrame 개요 & 생성 및 저장
1. DataFrame 개요
- 표(테이블-행렬) - 정형데이터를 다루는 Pandas 클래스
- 데이터베이스의 Table이나 R의 data.frame이나 Excel의 표 와 동일한 역할
- 분석할 데이터를 가지는 판다스의 가장 핵심적인 클래스
- 행 이름: index 열 이름: column
- 행이름과 열이름은 명시적으로 지정할 수 있다.
- 명시적으로 지정하지 않으면 순번 (0부터 1씩 증가) 이 index, column 명으로 사용된다.
- 직접 데이터를 넣어 생성하거나, 데이터 셋을 파일(csv, 엑셀, DB 등)로 부터 읽어와 생성한다.
- 하나의 행과 하나의 열은 Series로 구성된다.
- 1행 / 1열 -> series
- n행 / n열 -> dataframe
- 2차원의 의미 : axis 축이 두개 - > 행과 열 - > 식별자가 두 개이다. - > 해당 값을 의미하는 식별자가 행과 열. 두 개
- > 행 식별자는 index, 열 식별자는 column
- 정형데이터(형식이 정해진, 구조화된 형태) - 표(테이블-행렬)
- 비정형데이터(형식이 정해지지 않는) - 텍스트, 이미지, 음성, 영상
- 준정형데이터(약간의 정형. 구조에 따라 저장된 데이터지만 정형 데이터와 달리 데이터 내용 안에 구조에 대한 설명이
함께 존재) - HTML, XML
2. DataFrame 생성
직접 생성
pd.DataFrame(data, [index=None, columns=None])
- data
- DataFrame을 구성할 값을 설정
- 방법1 ) Series, List, ndarray(넘파이 배열)를 담은 2차원 배열를 data로 넣는다.
- 방법2 ) 열이름을 key로 컬럼의 값 value로 하는 딕션어리(사전)를 data로 넣는다.
- index
- index명 으로 사용할 값 배열로 설정
- columns
- 컬럼명 으로 사용할 값 배열로 설정
(1) dictionary를 이용해 DataFrame 생성
컬럼명:[컬럼값들, ...]
: key값은 컬럼명이 되고, 각 컬럼의 데이터로 리스트에 담은 값들이 들어감.
- 원소들의 개수가 같아야 한다.
- > 표가 되어야 한다. 사각형 형태! 표 형태! 어떤 것은 몇행 어떤 것은 몇 행 이러면 안됨.
d = {
'id':['id-1','id-2','id-3','id-4','id-5'],
'korean':[100,50,70,90,85],
'math':[80,50,90,100,100]
}
grade = pd.DataFrame(d)
grade- 현재, index 명 지정해주지 않아서 default 순번으로 들어간다.

(2) 2차원 형태의 리스트(배열)을 이용해 생성
어떻게 행과 열이 데이터 프레임이 생성되는지 정확히 이해해야 한다.
lst = [
['my-1', 20, 50],
['my-2', 70, 20],
['my-3', 100, 50],
['my-4', 70, 100],
['my-5', 60, 80],
['my-6', 100, 100]
]
grade2 = pd.DataFrame(lst)
grade2
- 현재, 컬럼, 인덱스 지정 안 해서 default 순번으로

(3) 2차원 형태의 리스트(배열)을 이용해 생성 - columns과 index 지정
- 보통 컬럼명 지정은 순번보단 이름 지정해준다.
- 보통 인덱스명은 이름 지정 안 하고 순번으로 쓴다.
lst = [
['my-1', 20, 50],
['my-2', 70, 20],
['my-3', 100, 50],
['my-4', 70, 100],
['my-5', 60, 80],
['my-6', 100, 100]
]
grade2 = pd.DataFrame(lst, columns=['ID','국어','수학'],index=list('가나다라마바'))
grade2
2. DataFrame 파일로 저장
이렇게 생성한 데이터는 메모리에 있다. 끄면 사라지기에 파일로 저장해야 한다.
- 보통 csv로 저장. 메모장만 있으면 볼 수 있는.
- excel도 되지만 잘 안씀. excel 호환 프로그램이 필요하기에.
DataFrame객체.to_파일타입()
# csv 저장 (텍스트 파일로 저장)
DataFrame객체.to_csv(파일경로,sep=',', index=True, header=True, encoding)
# excel 저장
DataFrame객체.to_excel(파일경로, index=True, header=True)
- 파일경로: 저장할 파일경로(경로/파일명)
- sep : 데이터 구분자 (default ' , ')
- index, header : 인덱스/헤더 저장 여부
- encoding
- 파일인코딩
- 생략시 운영체제 기본 encoding 방식
(1) import os 모듈 사용
# DataFrame의 데이터를 저장할 디렉토리 생성.
# 디렉토리 위치가 담긴 save_dir 변수를 아래 예제해서 계속 사용할 것이다.
import os
# DataFrame의 데이터를 저장할 디렉토리 생성 # 상대경로 './save_data' 에서 ./ 생략한 것.
save_dir = 'save_data'
if not os.path.isdir(save_dir): # 디렉토리가 없으면
os.mkdir(save_dir) # save_data라는 디렉토리를 생성.(2) 경로 지정
- 저장할 파일 경로를 지정하는 방법1
이것보다 아래 방법을 쓴다.
save_file_path = save_dir + "/grade1.csv"
print(save_file_path)
save_data\grade.csv- 저장할 파일 경로를 지정하는 방법2
save_file_path = os.path.join(save_dir,'grade.csv')
print(save_file_path)
save_data\grade.csv(3) 저장
grade.to_csv(save_file_path)
- index와 column을 default 로 저장 시, index 명과 컬럼 명도 저장이 된다.

- index명을 저장하지 않겠다면 index = False
(보통, 1씩 증가하는 정수를 index명으로 사용한 경우 저장하지 않는다.)
grade.to_csv(save_file_path, index=False)
인덱스 순번이 의미 없는, 필요 없는 데이터라면 애초에 저장하지 말자.
나중에 읽어올 때 데이터로 처리해버릴 수 있다.
- column 명도 저장하지 않겠다면
(보통 column명은 함께 저장함.)
grade.to_csv(save_file_path2, index=False, header=False)
- 열(값) 구분자를 설정 (default : ',')
(읽어올 때도 설정한 구분자에 맞게 해줘야 함.)
grade.to_csv(save_file_path3, index=False, sep='|')
(4) 다른 파일 형식 저장
- excel 저장_ 이를 위해 다음 모듈 설치
!pip install xlwt# excel로 저장
save_file_path4 = os.path.join(save_dir, 'grade.xls')
grade.to_excel(save_file_path4, index=False)
- pickle로 저장
save_file_path5 = os.path.join(save_dir, 'grade.pkl')
grade.to_pickle(save_file_path5)
- html로 저장
save_file_path6 = os.path.join(save_dir, 'grade.html')
grade.to_html(save_file_path6)2. 파일로 부터 데이터셋을 읽어와 생성하기
2.1 csv 파일 등 텍스트 파일로 부터 읽어와 생성
pd.read_csv(파일경로, sep=',', header, index_col, na_values, encoding)- 파일경로 : 읽어올 파일의 경로
- sep
- 데이터 구분자.
- 기본값: 쉼표
- header = 정수
- 열이름(컬럼이름)으로 사용할 행 지정
- 기본값: 첫번째 행은 컬럼으로 읽는다.
- None 설정: 첫번째 행부터 데이터로 사용하고, header(컬럼명)는 0부터 자동증가하는 값을 붙인다.
- index_col = 정수,컬럼명
- 특정 컬럼을인덱스으로 뽑아낼 때.
- index 명으로 사용할 열이름(문자열)이나 열의 순번(정수)을 지정.
- 기본값 : 생략시 0부터 자동증가하는 값 순번을 붙인다.
- na_values
- 읽어올 데이터셋의 값 중 결측치로 처리할 문자열 지정.
- encoding
- 파일 인코딩
- 생략시 운영체제 기본 encoding 방식 UTF_8 로 저장
(1) header 기본값 : 읽어올 파일에서 첫번째 행은 컬럼으로 읽는다.
index_col 기본값 : 자동으로 0부터 순번으로 인덱스
- index가 파일에 저장되어있지 않은 상황
# save_file_path = 'save_data/grade1.csv'
grade_df1 = pd.read_csv(save_file_path)
grade_df1
- index 순번이 파일에 함께 저장이 되어있는 상황
index 기본값을 설정하면,
첫번째 열이 인덱스 였음에도 이를 인덱스 명으로 인식하지 못한다.
그렇기에, 자동으로 0부터 순번으로 인덱스가 지정된다. 인덱스명인데 데이터로 저장되게 됨.

애초에 의미없는 index 순번이라면 저장하지 말자.
(2) 인덱스명 지정
header 기본값 : 읽어올 파일에서 첫번째 행은 컬럼으로 읽는다.
index_col = 0
=> 위 문제를 해결하기 위해, 첫번째 열을 인덱스 명으로 지정해준다.
pd.read_csv('save_data/test_grade.csv',index_col=0)
(3) 컬럼명 header 지정
header = None : header행이 없다라는 설정.
- > 순번(0,1,2,...)이 컬럼명이 된다.
names=['ID','korean','Math'])
- > names=[컬럼명] 이 컬럼명으로 지정해준다.
index_col 기본값
- 데이터프레임이 지금 컬럼명이 지정되어 있지 않은 상황
- header 설정을 하지 않으면 ( default ), 첫번째 행을 컬럼명으로 읽는다.
이 상황에서 그렇다면 첫번째 행을 데이터가 아닌, 컬럼으로 지정하게 된다.
-> header행을 지정해줘야 한다.
grade_df3 = pd.read_csv(save_file_path2, header=None, names=['ID','korean','Math'])
grade_df3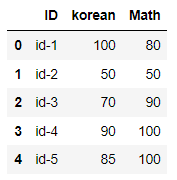
(4) 구분자 설정
default : , 쉼표
- 쉼표 , 구분자가 아닌데 아무 설정을 안 해주면 데이터를 구분하지 못하고 한 행을 통으로 하나의 데이터로 볼 것.
- > 어떤 구분자로 구분하고 있는지 말해줘야 함.
grade_df3 = pd.read_csv(save_file_path3, sep='\t')
(5) 결측치 설정
- 데이터 프레임 내 문자열 '결측치' 를 값이 아니라 NA로 읽어들여라.
grade_df5 = pd.read_csv(save_file_path2, header=None, na_values=['결측치'])2.2 엑셀파일 읽기
- 엑셀 읽기 위해 install
!pip install xlrdgrade_df6 = pd.read_excel('save_data/grade.xls')pd.read_csv(경로)
s1.to_csv(경로)
'AI_STUDY > Pandas' 카테고리의 다른 글
| Pandas _ 02-4 DataFrame 접근 _ 컬럼/행의 값 조회 및 변경 (0) | 2022.06.08 |
|---|---|
| Pandas _ 02-3 DataFrame 접근 _ 컬럼/행 조회 및 변경 (0) | 2022.06.08 |
| Pandas _ 02-2 DataFrame 주요 메소드, 속성 (0) | 2022.06.08 |
| Pandas _ 01-2 Series 주요 메소드 , 속성 (0) | 2022.06.07 |
| Pandas _ 01-1 pandas 개요, Series 생성 및 접근 (0) | 2022.06.03 |



