
ㅅㅇ
머신러닝 _ 06_1_과적합 일반화와 그리드 서치 본문
플레이데이터 빅데이터캠프 공부 내용 _ 7/4
머신러닝 _ 06_1_과적합 일반화와 그리드 서치
1. 일반화, 과적합
1) Generalization (일반화)
- 모델이 새로운 데이터셋(테스트 데이터)에 대하여
정확히 예측하면 이것을 (훈련데이터에서 테스트데이터로) 일반화 되었다고 말한다.
- 모델이 훈련 데이터로 평가한 결과와 테스트 데이터로 평가한 결과의 차이가 거의 없고 좋은 평가지표를 보여준다.
2) Overfitting (과대적합)
- 모델이 훈련 데이터에 대한 예측성능은 너무 좋지만
일반성이 떨어져 새로운 데이터(테스트 데이터)에 대해선 성능이 좋지 않은 것을 Overfitting이라고 한다.
- 이는 모델이 훈련 데이터 세트의 특징을 너무 맞춰서 학습 되었기 때문에 일반화 되지 않아
(필요하지 않는 것 까지 모델이 학습되어 새로운 데이터를 평가하는데 방해)
새로운 데이터셋(테스트세트)에 대한 예측 성능이 떨져 발생한다.
3) Underfitting (과소적합)
- 모델이 훈련 데이터과 테스트 데이터셋 모두에서 성능이 안좋은 것을 말한다.
- 모델이 너무 간단하여 훈련 데이터에 대해 충분히 학습하지 못해
데이터셋의 패턴들을 다 찾아내지 못해서 발생한다.

2. 과적합의 원인
1) Overfitting (과대적합) 의 원인
- 학습 데이터 양에 비해 모델이 너무 복잡한 경우 발생.
- 데이터의 양을 늘린다.
- 시간과 돈이 들기 때문에 현실적으로 어렵다.
- 모델을 좀더 단순하게 만든다.
- 사용한 모델보다 좀더 단순한 모델을 사용한다.
= > 모든 모델은 모델의 복잡도를 변경할 수 있는 규제와 관련된 하이퍼파라미터를 제공하는데 이것을 조절한다.
2) Underfitting(과소적합) 의 원인
- 데이터 양에 비해서 모델이 너무 단순한 경우 발생
- 좀더 복잡한 모델을 사용한다.
= > 모델이 제공하는 규제 하이퍼파라미터를 조절한다.
3. 규제 하이퍼파라미터란?
- 모델의 복잡도를 규제하는 하이퍼파라미터로 Overfitting이나 Underfitting 이 난 경우
이 값을 조정하여 모델이 일반화 되도록 도와준다.
- 이 규제 하이퍼파라미터들은 모든 머신러닝 모델마다 있다.
1) 하이퍼파라미터 (Hyper Parameter) 란?
- 모델의 성능에 영향을 끼치는 파라미터 값으로 모델 생성시 사람이 직접 지정해 주는 값(파라미터)
2) 하이퍼파라미터 튜닝(Hyper Parameter Tunning)
- 모델의 성능을 가장 높일 수 있는 하이퍼 파라미터를 찾는 작업
3) 파라미터(Parameter)
- 머신러닝에서 파라미터는 모델이 데이터 학습을 통해 직접 찾아야 하는 값을 말한다.
4. 하이퍼파라미터 튜닝 예시 : DesicionTreeClassifer - 직접 반복문으로
1) 트리 구조 시각화 - graphviz 이용
: DecisionTree 가 어떤 기준으로 데이터를 나누었는지를 graphviz 툴과 연동하여 시각화 (** 다운 필요)
ex ) 위스콘신 유방암 데이터셋 모델링
- 데이터 로딩 및 set 분리, 모델 생성, 학습
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.datasets import load_breast_cancer, load_iris
from sklearn.model_selection import train_test_split
cancer = load_breast_cancer()
X = cancer.data
y = cancer.target
X_train, X_test, y_train, y_test = train_test_split(X,y,stratify=y, random_state=0)
# 모델생성
tree = DecisionTreeClassifier(max_depth=3, random_state=0)
# 학습
tree.fit(X_train, y_train)
- 모델 시각화
# 학습한 DecisionTree 모델을 시각화할 수 있도록 추출해주는 함수
from sklearn.tree import export_graphviz
# 시각화 해주는 함수
from graphviz import Source
graph = Source(export_graphviz(tree, # 학습된 DecisionTree 모델(이것만 필수)
out_file=None, # 시각화된 것을 파일로 저장하기 위한 경로
feature_names=cancer.feature_names, # feature 이름(컬럼명) 리스트
class_names=cancer.target_names, # Label의 class를 지정하면 각 노드에 다수Label가 무엇인지 출력
rounded=True,
filled=True)) # 각 노드를 배경색을 시각화 -> 다수 클래스별로 색을 맞춰서 배경을 칠한다.
graph
- 출력
- 제일 위 : root
- 가지 안 치는 애들 가장 마지막 : leaf
- 출력된 노드 : 다수의 class는 benign ( 426개 중 267 개의 데이터)
# 현재 데이터를 나누기 위한 질문
# (아래에 적혀져 있는 상태에서 이 질문을 하겠다라는 의미. 이질문을 해서 아래 노드가 된 게 아님.)
worst perimeter <= 106.1
-----------------------------
# 현재 노드의 상태
gini = 0.468 # label들이 얼마나 섞여있냐 # 불순도율(0 ~ 0.5: 0-하나의 클래스값으로만 구성. 0.5- 모든 클래스들이 동일한 비율로 구성.)
samples = 426 # 총 데이터 수
value = [159,267] # class 별 데이터 개수. [label 0의 개수, label 1의 개수]
class = benign # 다수 class 의 class 이름
- 출력된 노드 : leaf node 이여야 한다.
samples = 240
value = [1,239]
class = benign
0일 확률 :0.4% 1일 확률 : 99.6% 로 1이 유력하다.
새로운 데이터가 들어와 추론을 한다면 그림처럼 트리 모델 질문을 통해 계속해서 단하나의 class 가 남도록 할 것이다.
그리고 만약 과대적합이라면, 새로운 데이터 셋이 들어왔을 때 잘 못 판단할 것이다.
그렇기에 학습이 덜 되도록 규제를 시켜,
끝까지 완벽하게 나눠질 필요 없이, 현 노드 상태에서 멈춰지게 해야 한다.
이를 위해 과대 적합을 막아주는 튜닝이 필요하다.
2) Decision Tree 복잡도 제어(규제 파라미터)
- Decision Tree 모델을 복잡하게 하는 것은 노드가 너무 많이 만들어 지는 것이다.
- 노드가 많이 만들어 질수록 훈련데이터셋에 Overfitting 된다.
== > 적절한 시점에 트리 생성을 중단해야 한다.
- 모델의 복잡도 관련 주요 하이퍼파라미터
(1) max_depth : 트리의 최대 깊이
- none : 끝까지 나눈다.
- 1로 갈수록 단순. 너무 단순하면 train test 둘다 안 좋음
- 커질 수록 둘 다 좋아지다가 어느 시점에서 test 성능이 떨어진다. 그때가 과대적합이 시작되는 시점.
- 제일 좋아진 지점을 찾아야 한다. max depth를 늘려가면서
- 너무 커진다면?
- 오버피팅. 데이터에 비해 복잡하게 학습을 하는 것. 질문을 너무 많이 함 = > depth 낮춰야 한다.
(2) max_leaf_nodes : 리프노드 개수
(3) min_samples_leaf : leaf 노드가 되기위한 최소 샘플수. (데이터 수)
가지를 칠 최소 샘플 수 (samples 값 이 이 갯수 이하로 안 떨어진다. )
(4) min_samples_split : 나누는 최소한의 샘플수.
3) 최적의 하이퍼파라미터 max_depth 찾기 - 반복문을 돌려서
# 데이터는 아까 위에서 분리한 위스콘신 유방암 데이터 셋
- 모델 학습 : max_depth = 1 ~ 5 제어 및 추론, 평가
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 1~5 (max_depth 후보들)
max_depth_candidates = range(1,6)
# max_depth 별 train/test set의 평가 결과를 저장할 리스트
train_acc_list = []
test_acc_list = []
for depth in max_depth_candidates:
tree = DecisionTreeClassifier(max_depth=depth, random_state=0)
tree.fit(X_train, y_train)
pred_train = tree.predict(X_train)
pred_test = tree.predict(X_test)
train_acc_list.append(accuracy_score(y_train, pred_train))
test_acc_list.append(accuracy_score(y_test, pred_test))
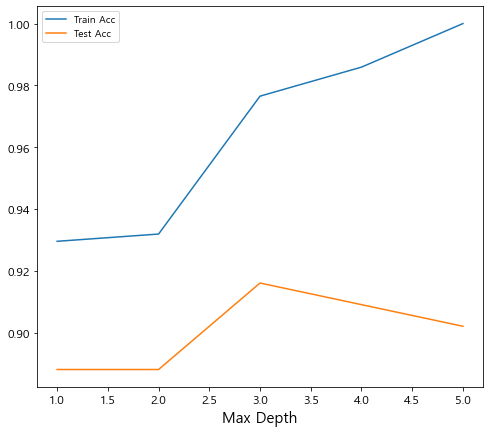
- max_depth 조정에 따른 accuracy 평가를 데이터프레임 과 그래프로 확인
import pandas as pd
result_df = pd.DataFrame({'Train Acc':train_acc_list,
'Test Acc':test_acc_list},
index=max_depth_candidates
)
# 축에 대한 이름을 지정. index/컬럼명의 name을 지정해줌.
result_df.rename_axis('Max Depth', inplace=True)
result_dfresult_df.plot(figsize=(8,7))
plt.show()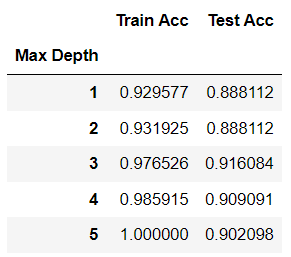
근데 모델엔 하이퍼 파라미터가 하나만 있는 것이 아니다.
여러 개의 하이퍼 파라미터를 다 테스트 해야하는데, 이를 위처럼 반복문으로 할 수 있을까?
그래서 우리는 grid search 방식을 통해
모든 조합들을 다 테스트 해보고 가장 높은 성능을 내는 하이퍼 파라미터를 찾고자 한다.
5. Grid Search 를 이용한 하이퍼파라미터 튜닝
- 모델의 성능을 가장 높게 하는 최적의 하이퍼파라미터를 찾는 방법.
- 하이퍼파라미터 후보들을 하나씩 입력해 모델의 성능이 가장 좋게 만드는 값을 찾는다.
5.1 종류
1) Grid Search 방식 : 모든 조합을 다 찾는 방식
- sklearn.model_selection.GridSearchCV
- 시도해볼 하이퍼파라미터들을 지정하면
모든 조합에 대해 교차검증 후 제일 좋은 성능을 내는 하이퍼파라미터 조합을 찾아준다.
- 적은 수의 조합의 경우는 괜찮지만 시도할 하이퍼파라미터와 값들이 많아지면 너무 많은 시간이 걸린다.
2) Random Search 방식 : 전체중에 내가 정한 갯수만. 랜덤하게 함.
- sklearn.model_selection.RandomizedSearchCV
- GridSeach와 동일한 방식으로 사용한다.
- 모든 조합을 다 시도하지 않고 임의로(램덤하게) 몇개의 조합만 테스트 한다.
- 60회 정도 하면 다 한것과 같이 비슷하게 나온다.
그리고 나온 결과의 근처가 최적과 가까울 것이다.
= > 그래서 이 결과를 gird search 를 하여 최고 성능 하이퍼파라미터 조합을 찾는다.
5.2.1 GridSearchCV 매개변수, 메소드, 결과 조회 속성
1) Initializer 매개변수
- estimator : 모델객체 지정
- params_grid : 하이퍼파라미터 목록을 dictionary로 전달
형식 : { '파라미터명' : [파라미터값 list] ... }
- scoring : 평가 지표
- 평가지표문자열: https://scikit-learn.org/stable/modules/model_evaluation.html
- 생략시, 분류는 accuracy, 회귀는 R^2 를 기본 평가지표로 설정한다.
- 여러개일 경우 List로 묶어서 지정
- refit : best parameter를 정할 때 사용할 평가지표. 이를 기준으로 순위 정렬.
- scoring에 여러개의 평가지표를 설정한 경우 refit을 반드시 설정해야 한다.
- cv : 교차검증시 fold 개수.
- n_jobs : 사용할 CPU 코어 개수 (None:1(기본값), -1: 모든 코어 다 사용)
2) 메소드
- .fit(X, y) : 학습
- .predict(X) : 분류 - 추론한 class. 회귀 - 추론한 값
== > 제일 좋은 성능을 낸 모델로 predict()
- predict_proba(X) : 분류문제에서 class별 확률을 반환
- 제일 좋은 성능을 낸 모델로 predict_proba() 호출
3) 결과 조회 속성
- fit() 후에 호출 할 수 있다.
- cv_results_ : 파라미터 조합별 평가 결과를 Dictionary로 반환한다.
- best_params_ : 가장 좋은 성능을 낸 parameter 조합을 반환한다.
- best_estimator_ : 가장 좋은 성능을 낸 모델을 반환한다. 이를 받아 테스트 평가
- best_score_ : 가장 좋은 점수 반환한다.
5.2.2 GridSearchCV 예시 (한 가지 성능 지표 확인)
1) GridSearchCV 생성
- 파라미터 후보 : 딕셔너리
=> key - 하이퍼파라미터이름(매개변수이름), value - 후보를 리스트로
- grid search는 내부적으로 cross validaiton 교차 검증 한다.
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
# default 값 말고 다른 값을 대입할 것인데, 고정시킬 것은 객체 생성하면서 설정한다.
tree = DecisionTreeClassifier(random_state=0)
# 파라미터 후보
param_grid = {'max_depth':[None, 1, 2, 3, 4, 5],
'max_leaf_nodes':[3,5,7,9]
} # 나머지 하이퍼파라미터는 default 값 사용
# GridSearchCV 생성
grid_search = GridSearchCV(tree, # 모델
param_grid=param_grid, # 하이퍼파라미터후보
scoring='accuracy', # 평가지표
cv=5, # Cross validation 의 folder 개수. 보통 4 아니면 5
n_jobs=-1) # 사용할 cpu 개수 : -1는 모든 cpu 프로세스 다 사용하겠다. 항상 -1 주면 됨. (조합별로 병렬 학습)
2) 학습
# 6x4(조합) x 5(folder) =120 번 함.
grid_search.fit(X_train, y_train)GridSearchCV(cv=5, estimator=DecisionTreeClassifier(random_state=0), n_jobs=-1,
param_grid={'max_depth': [None, 1, 2, 3, 4, 5],
'max_leaf_nodes': [3, 5, 7, 9]},
scoring='accuracy')
3) 결과 확인 cv_results_ : 파라미터 조합별 평가 결과를 Dictionary 로 반환
grid_search.cv_results_
- cv_results_ 파라미터 조합별 평가 결과에는 아래와 같은 값들이 있다.
Index(
# 걸린 시간
['mean_fit_time', 'std_fit_time', 'mean_score_time', 'std_score_time',
'param_max_depth', 'param_max_leaf_nodes',
# 조합 파라미터
'params',
# split 0 ~ 4 별로. mean. std.
'split0_test_score', 'split1_test_score', 'split2_test_score',
'split3_test_score', 'split4_test_score',
'mean_test_score', 'std_test_score',
# rank 순위
'rank_test_score'],
dtype='object')
- 조회 결과를 데이터 프레임으로 보기
- rank 별로 정렬
- 동일한 순위라면 가장 먼저 한 게 앞에 나옴.
- 보통, 동일한 순위라면 표준편차가 더 작은 것을 선택한다.
- 지금은 표편도 같아서 아무거나 해도 됨.
import pandas as pd
df = pd.DataFrame(grid_search.cv_results_)#.sort_values('rank_test_score')#.filter(like='rank')
df[df.columns[6:]].sort_values('rank_test_score')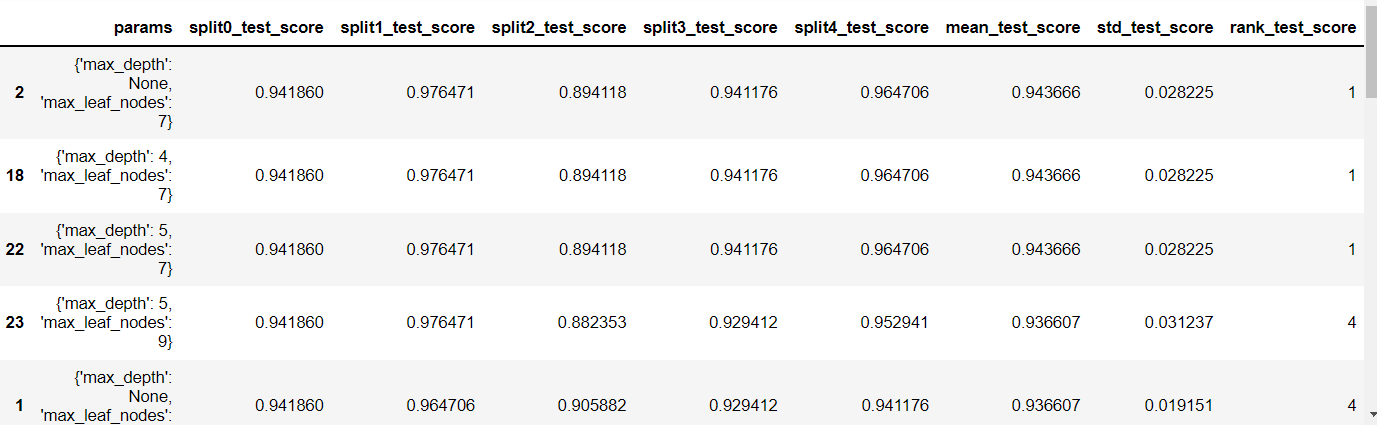
4) 결과 확인 best_params : 가장 좋은 성능을 낸 parameter 조합을 반환
print("가장 좋은 파라미터 조합:",grid_search.best_params_)가장 좋은 파라미터 조합: {'max_depth': None, 'max_leaf_nodes': 7}
5) 결과 확인 best_score_ : 가장 좋은 점수 반환
print("가장 좋은 평가점수: ",grid_search.best_score_)가장 좋은 평가점수: 0.9436662106703146
6-1) best_model.predict(X_test)
# best_estimator : best하이퍼 파라미터로 학습된 모델을 제공
best_model = grid_search.best_estimator_
accuracy_score(y_test, best_model.predict(X_test))
6-2) grid_search.predict(X_test)
# grid_search.predict() 추론 => best_estimator_를 이용해서 추론
accuracy_score(y_test, grid_search.predict(X_test))
5.2.3 GridSearchCV 예시 (여러 성능 지표 확인)
- 여러 성능지표는 확인할 수 있지만, 최적의 파라미터를 찾기 위해서는 하나의 지표만 사용한다.
- scoring에 리스트로 평가지표들 묶어서 설정
- refit에 최적의 파라미터 찾기 위한 평가지표 설정
1) GridSearchCV 생성
tree = DecisionTreeClassifier(random_state=0)
param_grid = {'max_depth':[None, 1, 2, 3, 4, 5],
'max_leaf_nodes':[3,5,7,9]
}
grid_search = GridSearchCV(tree,
param_grid=param_grid,
scoring=['accuracy', 'recall', 'precision','roc_auc', 'f1'],
refit='accuracy', # 순위 기준이 될 평가지표
cv=5,
n_jobs=-1)
2) 학습
grid_search.fit(X_train,y_train)
3) 결과 확인 cv_results_ : 모든 평가 지표에 대해서 다 보여줌.
df2 = pd.DataFrame(grid_search.cv_results_)
df2.columns
Index(['mean_fit_time', 'std_fit_time', 'mean_score_time', 'std_score_time',
'param_max_depth', 'param_max_leaf_nodes', 'params',
'split0_test_accuracy', 'split1_test_accuracy', 'split2_test_accuracy',
'split3_test_accuracy', 'split4_test_accuracy', 'mean_test_accuracy',
'std_test_accuracy', 'rank_test_accuracy', 'split0_test_recall',
'split1_test_recall', 'split2_test_recall', 'split3_test_recall',
'split4_test_recall', 'mean_test_recall', 'std_test_recall',
'rank_test_recall', 'split0_test_precision', 'split1_test_precision',
'split2_test_precision', 'split3_test_precision',
'split4_test_precision', 'mean_test_precision', 'std_test_precision',
'rank_test_precision', 'split0_test_roc_auc', 'split1_test_roc_auc',
'split2_test_roc_auc', 'split3_test_roc_auc', 'split4_test_roc_auc',
'mean_test_roc_auc', 'std_test_roc_auc', 'rank_test_roc_auc',
'split0_test_f1', 'split1_test_f1', 'split2_test_f1', 'split3_test_f1',
'split4_test_f1', 'mean_test_f1', 'std_test_f1', 'rank_test_f1'],
dtype='object')
4) 결과 확인 cv_results_ : 데이퍼 프레임으로
df2[df2.columns[6:]].sort_values('rank_test_accuracy')
5) 결과 확인 best_score_
grid_search.best_score_0.9436662106703146
6) 결과 확인 best_params_
grid_search.best_params_{'max_depth': None, 'max_leaf_nodes': 7}
7) best model을 이용해 Test set 최종평가
7.1)
accuracy_score(y_test, grid_search.predict(X_test))0.9370629370629371
7.2)
from sklearn.metrics import roc_auc_score
best_model = grid_search.best_estimator_
# accuracy_score에다가 roc_auc_score 까지 보기.
accuracy_score(y_test, best_model.predict(X_test)), roc_auc_score(y_test, best_model.predict_proba(X_test)[:,1])
(0.9370629370629371, 0.9505241090146751)
5.3 RandomizedSearchCV 매개변수, 메소드, 결과 조회 속성
1) Initializer 매개변수
- estimator : 모델객체 지정
- params_grid : 하이퍼파라미터 목록을 dictionary로 전달
형식 : { '파라미터명' : [파라미터값 list] ... }
- scoring : 평가 지표
- 평가지표문자열: https://scikit-learn.org/stable/modules/model_evaluation.html
- 생략시, 분류는 accuracy, 회귀는 R^2 를 기본 평가지표로 설정한다.
- 여러개일 경우 List로 묶어서 지정
- refit : best parameter를 정할 때 사용할 평가지표. 이를 기준으로 순위 정렬.
- scoring에 여러개의 평가지표를 설정한 경우 refit을 반드시 설정해야 한다.
- cv : 교차검증시 fold 개수.
- n_jobs : 사용할 CPU 코어 개수 (None:1(기본값), -1: 모든 코어 다 사용)
2) 메소드
- .fit(X, y) : 학습
- .predict(X) : 분류 - 추론한 class. 회귀 - 추론한 값
== > 제일 좋은 성능을 낸 모델로 predict()
- predict_proba(X) : 분류문제에서 class별 확률을 반환
- 제일 좋은 성능을 낸 모델로 predict_proba() 호출
3) 결과 조회 속성
- fit() 후에 호출 할 수 있다.
- cv_results_ : 파라미터 조합별 평가 결과를 Dictionary로 반환한다.
- best_params_ : 가장 좋은 성능을 낸 parameter 조합을 반환한다.
- best_estimator_ : 가장 좋은 성능을 낸 모델을 반환한다. 이를 받아 테스트 평가
- best_score_ : 가장 좋은 점수 반환한다.
5.3.1 RandomizedSearchCV 예시
1) 데이터셋 로드 및 train/test set 나누기
import numpy as np
from sklearn.model_selection import RandomizedSearchCV
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y)
2) RandomizedSearchCV 생성
- criterion : 노드의 불순도를 계산하는 방식 지정. : gini, entropy
- 두 개의 성능 차이는 없음. gini가 def. 보통 gini 씀.
- scoring : 생략 시 기본 평가지표 - 분류 :accuracy, 회귀: r**2 (결정계수, r square)
tree = DecisionTreeClassifier(random_state=0)
#총 조합수 : 10*10*2 = 200
param_grid = {
"max_depth":range(1,11), # 10
"max_leaf_nodes":range(3,31,3), # 10
"criterion":["gini", "entropy"] # 2 : 노드의 불순도를 계산하는 방식 지정. => 지금은 두가지 다보기
}
n_iter_search = 50
random_search = RandomizedSearchCV(tree, # 모델
param_distributions=param_grid, # 파라미터 조합
n_iter=n_iter_search, # 50. 200개 조합 중 랜덤하게 50개만 선택해서 확인
# scoring = 'accuracy'
cv=4, # cross validation의 fold 개수
n_jobs=-1) # cpu 프로세스 몇 개에서 병렬로 학습할지 개수 지정.
3) 학습
# 최적의 파라미터 찾는 작업
random_search.fit(X_train, y_train)
4) 전체 결과 확인
- 200개 조합 중 50개. (하나의 행이 하나의 조합)
result_dict = random_search.cv_results_
result_dictresult_df[result_df.columns[7:]].sort_values('rank_test_score')
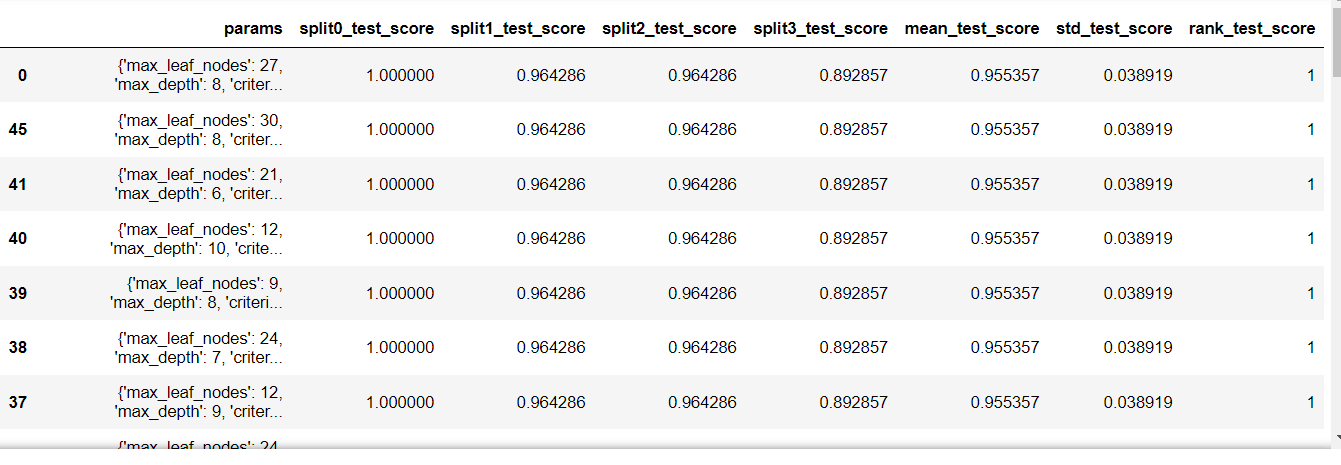
5) 결과 확인 best_params : 가장 좋은 성능을 낸 parameter 조합을 반환
# 공동 1등 중 가장 먼저 한 것
random_search.best_params_{'max_leaf_nodes': 27, 'max_depth': 8, 'criterion': 'gini'}
6) 결과 확인 best_score_ : 가장 좋은 점수 반환
random_search.best_score_0.9553571428571429
7) best model을 이용해 Test set 최종평가
accuracy_score(y_test, best_model.predict(X_test))0.9736842105263158accuracy_score(y_test, random_search.predict(X_test))0.9736842105263158'AI_STUDY > 머신러닝' 카테고리의 다른 글
| 머신러닝 _ 07_ 지도학습 _ 최근접이웃 (0) | 2022.07.10 |
|---|---|
| 머신러닝 _ 06_2_파이프라인 (0) | 2022.07.09 |
| 머신러닝 _ 04_데이터 전처리 (0) | 2022.07.01 |
| 머신러닝 _ 03_데이터셋 나누기와 교차검증 (0) | 2022.06.30 |
| 머신러닝 _ 02 머신러닝분석 - lris 분석 (0) | 2022.06.27 |


