
ㅅㅇ
머신러닝 _ 03_데이터셋 나누기와 교차검증 본문
머신러닝 프로세스 중 데이터 셋 분리에 대해 배울 것이다.
머신러닝 _ 03_데이터셋 나누기와 교차검증

1. 데이터셋(Dataset)
- Train 데이터셋 (훈련/학습 데이터셋)
: 모델을 학습시킬 때 사용할 데이터셋.
- Validation 데이터셋 (검증 데이터셋)
: 모델의 성능 중간 검증을 위한 데이터셋. 성능을 높이는 작업에서 쓰이는 데이터
- Test 데이터셋 (평가 데이터셋)
: 모델의 성능을 최종적으로 측정하기 위한 데이터셋
Test 데이터 셋은 마지막에 모델의 성능을 측정하는 용도로 한번만 사용되야 한다.
= = > 데이터셋을 Train set, Validation set, Test set으로 나눈다.
★ 왜 우리는 데이터 셋을 Train 데이터 셋, Validation 데이터셋, Test 데이터 셋 으로 나눌까?
- Train 셋은 당연히 패턴 을 찾은 학습으로 사용한 데이터이기에 이걸로 평가하는 것은 의미가 없다.
- 우리가 데이터 분석을 할 때, 모델을 훈련하고 평가했을때 원하는 성능이 나오지 않으면
데이터나 모델 학습을 위한 설정(하이퍼파라미터)을 수정한 뒤에 다시 훈련시키고 평가를 하게 된다.
즉, 원하는 성능이 나올때 까지 설정변경 -> 훈련 -> 평가를 반복하게 된다.
- 위 사이클을 반복하게 되면 평가결과를 바탕으로 설정(하이퍼파라미터)을 변경하게 되므로
모델이 평가할 때 사용한 데이터셋(Test set)에 모델이 맞춰서 훈련하는 것과 동일한 효과를 내게 된다.
(설정을 변경하는 이유가 Test set에 대한 결과를 좋게 만들기 위해, 성능 정확도를 올리기 위해 변경하므로)
- 그래서 Train dataset과 Test dataset 두개의 데이터셋만 사용하게 되면
평가용인 Test dataset 또한 fit 학습이 되는 효과를 내기에
평가용 데이터로 쓰여야 할 이 데이터는 모델의 성능을 제대로 평가할 수 없게 된다.
- 그래서 데이터셋을 train 셋, validation 셋, test 셋로 나눠
train set 와 validation set으로 모델을 최적화 한 뒤 마지막에 test set으로 최종 평가를 한다.
- train set과 validation set을 통해 성능 향상을 목표로 중간검증을 반복적으로 진행을 하고
test set (모델 입장에서는 아예 새로운 데이터들) 을 가지고 제일 마지막 최종 평가를 하는 것이다.
* 만약 test 셋 최종 평가에서 검증이 나오지 않아도 어쩔 수 없다. 최종 평가하면 끝.
근데 보통 val 데이터 셋으로 성능에 도달하면 test 셋에서도 도달한다.
2. 데이터 셋 분리 방식 1 : Hold Out
sklearn.model_selection.train_test_split()
: 하나의 데이터셋을 2 분할 해 주는 함수
- train_test_split() 매개변수
Feature(Input, X)
Target(Label, Output, y)
test_size =
: test 셋의 비율 (0.25 기본값)
random_state = 0
: random seed 설정
데이터가 분리될 때 random하게 shuffle 한다.
임의성 가지고 섞이기에 실행마다 달리지니 이를 유지하기 위해 seed 값 고정으로 막는다.
stratify =
: 분류문제에서만 설정.
분류 문제일 경우, 분할된 데이터셋의 class 별 데이터 수의 비율을 원본데이터셋과 동일하게 만들어준다.
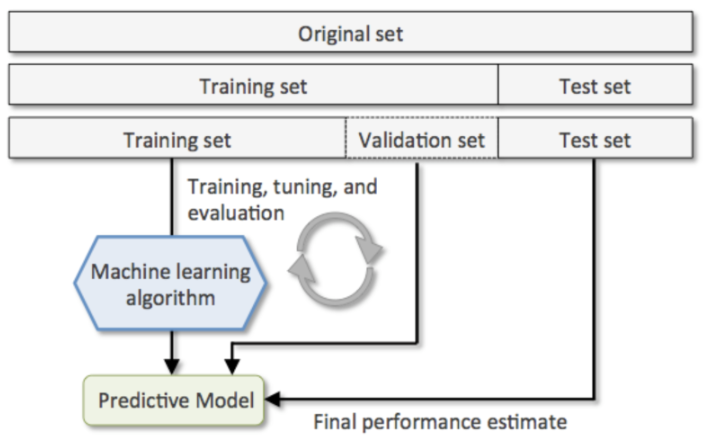
2 .1 Hold Out 방식으로 진행한 머신러닝
1 ) import
- 데이터셋을 2 분할하는 함수
: from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris # 토이 데이터셋 로딩 함수
from sklearn.model_selection import train_test_split # 데이터셋을 2 분할하는 함수
from sklearn.tree import DecisionTreeClassifier # 분류를 위한 DecisionTree 모델 클래스
from sklearn.metrics import accuracy_score # 정확도 평가를 해주는 함수
2 ) 데이터 불러오기
- 매개변수 retrun_X_y = True
: Feature와 target(label) 배열만 tuple에 묶어서 반환. 다 들고 올 필요 없으니
- 어차피 나눠서 쓸 것이니 튜플 대입으로 Feature 과 target 을 각각 X, y 변수에 담는다.
X, y = load_iris(return_X_y=True)
print(X.shape, y.shape) # 150 개의 데이터(150, 4) (150,)
- Feature 과 target 을 변수에 담을 때 X, y 로 표기하는 이유.
사실 상관없긴 한데,
feature의 경우, 속성으로 (150, 4) 과 같이 여러 개의 값으로 구성되어 있다. 즉, 집합의 개념 과 같다. = > 대문자
target 정답의 경우, 하나의 값 (150, )으로 구성되어 있다. = > 소문자
3 ) Train/Validation/Test set 분리
# 원본 Dataset = > Train/Test 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y, random_state=0)
# Train set => Train/Validation 분할
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.2, stratify=y_train, random_state=0)
- 같은 비율로 나눠졌는 지 확인
import numpy as np
print(np.unique(y_train, return_counts =True))
print(np.unique(y_val, return_counts =True))
print(np.unique(y_test, return_counts =True))(array([0, 1, 2]), array([32, 32, 32], dtype=int64))
(array([0, 1, 2]), array([8, 8, 8], dtype=int64))
(array([0, 1, 2]), array([10, 10, 10], dtype=int64))
4 ) 모델생성과 validation 검증 평가
하이퍼파리미터(hyper parameter) 튜닝 (tuning) 이란?
> 파라미터 : 모델 혹은 데이터에 의해 결정되는 파라미터
> 하이퍼파라미터 : 모델 생성할 때 우리가 설정해주는 설정값으로 모델 성능에 영향을 주는 파라미터.
> 하이퍼파리미터 튜닝 : 모델의 성닝이 좋아지도록 하이퍼파라미터 값을 변경
학습에 의해서가 아닌 사용자가 직접 세팅해주는 파라미터들을 의미한다.
예시. max _depth 값에 따라 정확도 성능이 달라진다. 이는 사용자가 직접 설정
- max_depth = 1 = > 0.666666
- max_depth = 2 = > 1
max_depth 와 같이 하이퍼 파라미터 조정 부분에서 우린 데이터 셋을 세 가지로 나누는 이유를 더 명확히 알 수 있다.
X_val 평가용 데이터에 맞춰서 val 데이터 셋의 성능 향상을 위해
max_depth 하이퍼 파라미터를 조정한다.
이렇게 학습과 검증 데이터를 반복적으로 돌며
X_val 에 맞춰 하이퍼파라미터 튜닝을 하니 더이상 val은 새로운 데이터가 아니다.
성능을 올리기 위해 검증용으로 쓰인 해당 데이터로 최종 평가를 하는 것이 과연 신뢰가 있을까?
그래서 test 셋 전혀 새로운 데이터 셋으로 최종 평가를 하는 것이다.
tree = DecisionTreeClassifier(random_state=0, max_depth=2)
# 학습-train
tree.fit(X_train, y_train)
# 평가 - validation 데이터 셋으로
pred_val = tree.predict(X_val)
val_acc = accuracy_score(y_val, pred_val)
print("val 정확도: ", val_acc)
5 ) test set으로 최종검증
test_pred = tree.predict(X_test)
accuracy_score(y_test, test_pred)
2.2 Hold Out 방식의 단점
- Hold Out 방식에서 모델의 성능 정확도는 train/validation/test 셋이 어떻게 나눠지냐에 따라 결과가 달라진다.
- 랜던성으로 나눠진다면 성능은 운에 따라 달라지는 것과 같을 것이다.
만약, test set에 이상치가 있다면 예측력은 떨어질 것이다.
- 데이터가 적을 경우 다양한 패턴을 찾을 수가 없다. 그렇다면
이상치에 대한 영향을 많이 받을 것이고 새로운 데이터에 대한 예측 성능이 떨어지게 된다.
- 데이터가 충분히 많을때는 변동성이 흡수되 괜찮다.
많으면 이상치가 패턴을 찾는 데에 영향력을 끼치지 않는다.
많다는 것의 의미는? 단순 많은 것이 아니라 다양한! 패턴의 data가 많아야하는 것이다.
= = > Hold out 방식은 (다양한 패턴을 가진) 데이터의 양이 많을 경우에 사용한다.
데이터을 많이 확보하여 Hold out 방식 하는 것이 제일 좋은 방식이다.
많다는 것의 의미는? 단순 많은 것이 아니라, '다양한! 패턴의 data' 가 많아야하는 것이다.
= = >그러나, 데이터 없을 땐 K - 겹 교차 검증 할 수 밖에 없다.
3. 데이터 셋 분리 방식 2 : K-겹 교차검증 (K-Fold Cross Validation)
1) 데이터셋을 설정한 K 개로 나눈다.
(K개 몇 개로 나눌 지는 우리가 정함. 나누고 난 하나의 단위를 Fold 라고 한다.)
2) K개 중 Fold 하나를 검증세트로 나머지 Fold 를 훈련세트로 하여 모델을 학습시키고 평가한다.
3) K개 모두가 한번씩 검증세트가 되도록 K번 반복하여 모델을 학습시킨 뒤
나온 평가지표들을 평균내서 모델의 성능을 평가한다.

- 데이터양이 충분치 않을때 사용한다.
- 보통 Fold를 나눌때 Train : test = 2.5:7.5 또는 2:8 비율이 되게 하기 위해 (2.5:7.5) 4개또는 (2:8) 5개 fold 로 나눈다.
- 종류 (외우기!)
- KFold
- 회귀문제의 Dataset을 분리할 때 사용
- 연속적인 값으로 다 다른 값이니 순서대로 나눠도 상관없음.
- StratifiedKFold
- 분류문제의 Dataset을 분리할 때 사용
- 이때 적당하게 잘 섞여야 하기에
3.1 KFold : 회귀문제 일 때
- 지정한 개수(K)만큼 분할한다.
- Raw dataset 행의 순서를 유지하면서 지정한 개수로 분할한다.
= > 연속적인 값을 다루는 회귀 문제에서는 기존에 정렬되어 있는 순서대로 나눠도 상관없음.
(1) 함수
- KFold(n_splits=K)
- 몇개의 Fold로 나눌지 지정
- KFold객체.split(데이터셋)
- 데이터셋을 지정한 K개 나눴을때 train/test set에 포함될 데이터의 index들을 반환하는 generator 생성
from sklearn.model_selection import KFold # KFold 클래스 - train_test_split 와 동일한 역할의 모듈
kfold = KFold(n_splits=3) # 객체생성 시 k 값(몇 개 fold로 나눌지 ) 지정
ex = kfold.split(X) # 객체.split(데이터셋) : index를 제공하는 generator를 반환. 반복자.
(2) 실제 사용 코드
- kfold.split()
: 데이터의 index들을 반환하는 generator 생성
현재 k = 3 로 데이터 셋을 세 fold 로 나눴다.
test 평가용 교차 검증은 fold 한 개로 하기 때문에
우린 train 과 test 셋은 2:1 로 나눈 결과를 볼 수 있을 것이고 교차 검증은 세 번을 하는 것이다.
kfold.split(데이터셋) 은 데이터셋들이 행 순서 그대로 2:1로 나누게 되었을 때의 index !! 를 반환하는 것이다.
데이터 셋은 이미 나눠진 게 아니라, 나누게 될 때의 index! 를 반환하는 것이다.
= > train set index, test set index 가 담긴 배열들이 튜플로 담겨져 있다.
그리고 이는 총 세 번의 검증을 위해 generator 로 생성된다.
= > 이 generator 는 튜플(train set index, test set index) 를 반환하게 되고
이를 train_index, test_index로 각각 받는다.
= > kFold generator가 제공한 index를 이용해(펜시인덱싱)
X 와 y 데이터 조회로 train set과 test set을 각각 추출하여
변수 X_train, X_test, y_trian, y_test 에 담아준다.
= > 담아준 데이터 셋 변수를 통해 모델 학습 추론 평가를 진행하게 된다.
이는 반복문을 돌며 각각 다르게 나눠진 데이터 셋에 대해 총 세번의 학습 추론 평가를 진행하게 된다.
이것이 바로 교차검증 !
여기서 각 fold 별로 검증 결과들을 모두 담아야 하므로 이를 담을 리스트를 미리 만들어준다.
# 각 fold별 검증 결과들을 담을 리스트
acc_train_list = [] # trainset 으로 평가한 결과
acc_test_list = [] # test dataset으로 평가한 결과
# kfold 객체 생성 - 3개 생성
kfold = KFold(n_splits=3)
for train_index, test_index in kfold.split(X): # split() generator 생성 = > 튜플(train set index, test set index) 반환.
# kFold generator가 제공한 index를 이용해(펜시인덱싱) data 조회
X_train, y_train = X[train_index], y[train_index] # train set 추출
X_test, y_test = X[test_index], y[test_index] # test set 추출
# 모델생성
tree = DecisionTreeClassifier()
# 학습
tree.fit(X_train, y_train)
# 추론
pred_train = tree.predict(X_train)
pred_test = tree.predict(X_test)
# 평가 - 정확도
acc_train = accuracy_score(y_train, pred_train) # (정답, 예측값)
acc_test = accuracy_score(y_test, pred_test)
acc_train_list.append(acc_train) # 평가 결과들을 list에 append(추가)
acc_test_list.append(acc_test)
3.2 StratifiedKold : 분류 문제일 때
- 나뉜 fold 들에 label들이 같은(또는 거의 같은) 비율로 구성 되도록 나눈다.
- 각각의 클래스 별로 각각 순서대로 나눈다.
(1) 함수
- StratifiedKold(n_splits=K)
- 몇개의 Fold로 나눌지 지정
- StratifiedKold객체.split(X, y)
- 데이터셋을 지정한 K개 나눴을때 train/test set에 포함될 데이터의 index들을 반환하는 generator 생성
- input(X)와 output(y) dataset을 전달한다. cf ) KFold 의 경우 X만 전달함. 주의 !
label 들이 같은 비율로 구성되어야 하니 당연히 y도 넣어주는 것.
from sklearn.model_selection import StratifiedKFold
s_fold = StratifiedKFold(n_splits=3)
ex = s_fold.split(X, y)
- train set index 와 test set index 를 통해 나눠질 y 값들에 모든 class 가 골고루 들어가 있는 지 확인 해보자.
# train set index로 y값을 조회 => class 별 개수 확인
np.unique(y[r[0]], return_counts=True)(array([0, 1, 2]), array([33, 34, 33], dtype=int64))# test set index로 y값을 조회 => class 별 개수 확인
np.unique(y[r[1]], return_counts=True)(array([0, 1, 2]), array([17, 16, 17], dtype=int64))(2) 실제 코드 적용
# Fold 별 검증 결과들을 담을 list
acc_train_list = []
acc_test_list = []
s_fold = StratifiedKFold(n_splits=3)
# 반복-튜플(train index, test index)
for train_index, test_index in s_fold.split(X, y):
# train/test 데이터셋 추출
X_train, y_train = X[train_index], y[train_index]
X_test, y_test = X[test_index], y[test_index]
# 모델생성
tree = DecisionTreeClassifier()
# 학습
tree.fit(X_train, y_train)
# 추론
pred_train = tree.predict(X_train)
pred_test = tree.predict(X_test)
# 평가
acc_train = accuracy_score(y_train, pred_train)
acc_test = accuracy_score(y_test, pred_test)
acc_train_list.append(acc_train)
acc_test_list.append(acc_test)
머신러닝 프로세스는 항상 일정하다.
split 폴더 나누는 갯수, 어떤 데이터 셋 X, y ? 어떤 알고리즘 모델? 어떤 평가지표?
이런 것들이 바뀌는 것이지, 전체적인 과정, 패턴은 똑같다.
그렇다면 이렇게 계속적인 코드를 짤 필요없이 함수화 할 수 있지 않을까?
4. cross_val_score( )
: 데이터셋을 K개로 나누고 K번 반복하면서 평가하는 작업을 처리해 주는 함수
- 주요매개변수
- estimator : 모델객체
- X: feature (input data)
- y: label (output data)
- scoring: 평가지표
- cv: 나눌 개수 (K)
- int : 개수
- KFold, StratifiedKFold 객체 를 넣는다.
- 반환값 : array - 각 반복마다의 평가점수
(1) iris data 셋을 3 개로 나누고, 3번 반복하여 accuracy 평가를 하는 작업
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_iris
import numpy as np
dt_clf = DecisionTreeClassifier(random_state=0)
iris_data = load_iris()
data = iris_data.data
label = iris_data.target
scores = cross_val_score(dt_clf , data , label , scoring='accuracy',cv=3)
print('교차 검증별 정확도:',np.round(scores, 4))
print('평균 검증 정확도:', np.round(np.mean(scores), 4))
(2) iris data 셋을 StratifiedKFold 으로 교차 검증 하는 작업
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_iris
import numpy as np
dt_clf = DecisionTreeClassifier(random_state=0)
iris_data = load_iris()
data = iris_data.data
label = iris_data.target
# kfold = KFold(n_splits=3)
kfold = StratifiedKFold(n_splits=3)
scores = cross_val_score(dt_clf , data , label , scoring='accuracy',cv=kfold)
print('교차 검증별 정확도:',np.round(scores, 4))
print('평균 검증 정확도:', np.round(np.mean(scores), 4))'AI_STUDY > 머신러닝' 카테고리의 다른 글
| 머신러닝 _ 06_2_파이프라인 (0) | 2022.07.09 |
|---|---|
| 머신러닝 _ 06_1_과적합 일반화와 그리드 서치 (0) | 2022.07.06 |
| 머신러닝 _ 04_데이터 전처리 (0) | 2022.07.01 |
| 머신러닝 _ 02 머신러닝분석 - lris 분석 (0) | 2022.06.27 |
| 머신러닝 _ 01 개요 (0) | 2022.06.27 |



