
ㅅㅇ
Pandas _ 04 groupby 관련메소드 및 일괄처리 메소드 본문
Pandas_04 groupby 관련메소드 및 일괄처리 메소드
그룹으로 묶인 애들을 집계말고 다른 처리가 가능하다.
1. filter()
DataFrameGroupBy.filter(func, dropna=True, *args, **kwargs)
- 처리 대상 : 그룹바이한 데이터프레임.
- 목적 : 특정 집계 조건을 만족하는 Group의 행들만 조회한다.
이때, 집계결과가 아닌 조건에 맞는 데이터 자체를 보고 싶은 것.
- 방법 (집계처리 비교 함수 만들기 -> filter문 작성)
1. 함수가 호출되면 'DataFrameGroupBy의 group로 한 group씩 DataFrame을 함수의 매개변수로 전달'한다.
2. 함수는 받은 DataFrame을 이용해 집계하여, 집계한 값의 조건을 비교해서 반환한다.(반환타입: Bool)
3. 반환값이 True인 Group들의 모든 행들로 구성된 DataFrame을 반환한다. -> filter
- 매개변수
- func: filtering 조건을 구현한 함수
- 사용자 정의 함수 객체
- 첫번째 매개변수로 "Group으로 묶인 DataFrame"을 받는다.
- dropna=True
- 필터를 통과하지 못한 group의 DataFrame의 값들을 drop시킨다.
- False로 설정하면, 조건에 만족하지 않는 행들도 NA 처리해서 반환한다.
- \*args, \*\*kwargs: filter 함수의 매개변수에 전달할 전달인자값.
** cf) df.filter (items , regex ..) : 데이터프레임에 대한. // 이름만 같음. 클래스 다름
(1) filter 기본 예제
ex ) 과일중 cnt1의 평균이 20 이상인 과일들만 보기
집계결과가 아니라 조건을 만족하는 행들을 다 출력하고 싶다.
** 아래 코드는 집계 결과. 이걸 보고 싶은 게 아님.
# 집계결과. 평균이 20이상인 과일들의 평균값을 확인하는 것.
r = df.groupby('fruits').mean()
i = r[r['cnt1']>=20]
i
# df[(df['fruits'] =='귤' )|( df['fruits'] == '딸기')] # 지금 이걸 보고 싶다.
- 함수정의 ( filter에 사용할 함수 )
매개변수 : x - (group별로 나뉜) dataframe을 받는다. (그룹 하나씩 받음. 그룹 4개면 네번 호출)
- 그룹으로 묶인 데이터프레임 행들 을 받는 것.
반환값 : bool - 특정 조건을 만족하는지 여부
받아온 데이터프레임 행들에서 cnt1 컬럼의 평균 계산해서 20 부터 큰지 여부를 확인하고 그 bool 결과를 return
def check_cnt1_mean(x):
return x['cnt1'].mean() >= 20
- 함수 호출 (filter 문 작성)
# 그룹별로 특정 조건을 만족하는 행들을 조회 해주는 함수
df.groupby('fruits').filter(check_cnt1_mean)filter 안에 함수 넣으면 그룹별 하나씩 함수 매개변수로 넣어주는 것.
- > 받아온 데이터프레임 행들에서
- > cnt1 컬럼의 평균 계산해서 20 부터 큰지 여부를 확인하고
- > 그 bool 결과를 return
- > 그룹 별 bool 결과를 보고 filtering 한다.
- lambda 식 구현
현재 함수는 단순 리턴으로 되어 있다. 그리고 이때, 일회성. 재사용 안 할거면.
df.groupby('fruits').filter(lambda x : x['cnt1'].mean() >= 20)
- dropna = True, False
defult : True
False로 설정하면, 조건에 만족하지 않는 행들도 NA 처리해서 반환한다.
df.groupby('fruits').filter(check_cnt1_mean, dropna = False)
df.groupby('fruits').filter(lambda x : x['cnt1'].mean() >= 20, dropna = False)
(2) 매개변수 있는 filter 함수 예제
위에는 어떤 컬럼을 조건에 들어가는 정수값이 뭔지를 함수에서 적어주었다.
이를 매개변수로 받으면 어떨까
- 함수 정의
[Parameter]
- x : DateFrame - group 별 DataFrame
- col_name : str - 평균을 계산할 컬럼명
- mean_thresh : int - 컬럼의 평균값이 이 값 인지 비교할 기준값
[return]
- bool : 컬럼의 평균이 mean_thresh 이상인지 여부
def check_mean(x, col_name, mean_thresh):
return x[col_name].mean() >= mean_thresh
- 함수 호출
키워드 인자 쓰는 게 좋다.
df.groupby('fruits').filter(check_mean, col_name ='cnt1', mean_thresh = 20)
df.groupby('fruits').filter(check_mean, col_name = 'cnt2', mean_thresh = 200)
** 람다는 일회성. 재사용하여 인자 받을 거면 람다식 쓸 필요 없음.
★ agg(fuct), filter(fuct), transfrom(fuct)
- > dataframeGroupby의 메소드 (어떤 집계를 할 지를 넣는데 그 종류가 두 개)
: 판다스 제공 집계함수 - 문자열, 사용자 정의 집계 함수 - 함수 객체
ex) df.groupby().agg() df.groupby().filter() df.groupby().transform()
filter 도 판다스 제공 집계함수로 가능한가? 사실상 불필요하긴 하지만
2. transform()
- 함수에 의해 처리된 값(반환값)으로 원래 값들을 변경(tranform) 해서 반환
- (값을 다 바꿈. 그룹별로 다 값 같게 됨.)
DataFrameGroupBy.transform(func, *args)
SeriesGroupBy.transform(func, *args)
- func : 매개변수로 그룹별로 Series를 받아 Series의 값들을 변환하여 (Series로)반환하는 함수객체
- DataFrameGroupBy은 모든 컬럼의 값들을 group 별 컬럼 별Series로 전달한다.
- *args : 함수에 전달할 추가 인자값이 있으면 매개변수 순서에 맞게 값을 전달한다. (위치기반 argument)
- df.groupby().transform() : 대상이 데이터프레임 즉, 값 대체가 전체의 컬럼에 적용도 가능하고
- df.groupby()["col1"].transform() : 대상이 series 즉, 특정 컬럼만 값 대체 적용도 가능하다.
둘 다 어쨋든
함수가 호출되었을 때, 매개변수가 전달할 때는 group 별 colum 별 series 로 전달된다.
[주 사용]
- transform() 함수를 groupby() 와 사용하면
컬럼의 각 원소들을 자신이 속한 그룹의 통계량으로 변환된 데이터셋을 생성할 수 있다.
- > DataFrame에 Group 단위 통계량을 추가할 때 유용하다. (그룹별로 데이터 값, 통계 값들을 같이 비교하고 싶을 때)
- 컬럼의 값과 통계값을 비교해서 보거나, 결측치 처리등에 사용할 수있다.
(1) 기본예제 : 판다스 제공 통계함수
특정 컬럼이 아니라, 데이터프레임 모든 컬럼에 적용
df.groupby('fruits').transform("mean")
(2) 기본예제 : 사용자 정의 통계함수
특정 컬럼이 아니라, 데이터프레임 모든 컬럼에 적용
- 매개변수 : Series (그룹별로 컬럼별로 -> series 단위로 )
- 반환 : 처리한 통계값
데이터프레임은 과일명을 기준으로 그룹화되었다. 그리고 transform 구문을 통해
그룹화된 데이터프레임에서 그룹별 그중에서도 컬럼별로 max_min_diff 매개변수에 담긴다.
전달된 series 는 집계 연산을 하고 return된다.
이렇게 그룹별, 컬럼별 모든 항목들이 다 호출되고
처리한 통계값들은 기존 데이터를 대신해 채운다.
def max_min_diff(x):
return x.max()-x.min()
df.groupby("fruits").transform(max_min_diff)
# lambda식
df.groupby("fruits").transform(lambda x : x.max()-x.min())
(3) 응용 예제 : 원본에 통계치 붙여서 비교하기
그냥 붙이면 가장 마지막 컬럼으로 붙는다.
우리는 평균 낸 대상 컬럼의 옆에 붙이고 싶다.
ex.) 특정 컬럼 cnt1 의 과일 별 평균을 df에 행별로 붙이기
- df.insert ( 컬럼을 삽입할 위치 순번, 컬럼명, 넣을 컬럼 값 )
=> 원본을 변경, 삽입하고 옆 컬럼 오른쪽으로 한 칸 씩 밀림
cnt1_mean = df.groupby('fruits')['cnt1'].transform('mean')
df.insert(2, 'cnt1_mean', cnt1_mean)
df
(4) sampling : 표본추출
- 행 중 랜덤하게 n 개를 추출하고 싶을 때 (알아서 섞임)
- frac = 샘플 비율(0~1 : 1= 100%, 0.1 = 10%)
df.sample(frac = 0.1)
# index명까지 섞인다.
fruits cnt1 cnt2
13 배 3 7.0
11 배 7 9.0
# 섞인 index명을 자동증가 정수로 변환시켜주기.
df.sample(frac = 0.1).reset_index(drop = True)
(5) 결측치 처리
- 결측치 : 모르는 값, 없는 값.
모르는 값이 있으면 분석하기 힘들다. 이 결측치를 처리해줘야 함.
- 결측치 처리
1. 제거 (행/열단위) : df.dropna(axis = 0)
- axis = 0 : 결측치가 있는 행(기본)을 제거
- axis = 1 : 결측치가 있는 열을 제거
- 행, 열 단위로 제거되면, 의미있는 데이터도 사라지게 된다.
= > 데이터 양이 충분할 때만 제거.
# 결측치가 있는 행(기본)로 제거
df.dropna()
# 결측치가 있는 열 제거
df.dropna(axis = 1)
2. 대체 : 바꿀 열(series). fillna(대체값)
- 결측치를 표현하는 값으로 대체 (NAN 대신 모르는 값이라는 의미를 담고있는)
- 가장 가능성이 높은 값을 대체 (평균, 중앙값, 최빈값)
- transform이용해서 결측치를 같은 그룹의 평균값으로 변환
= > 전체 평균보다 좀더 정확할 수 있다.
ex) cnt2 의 Na 결측치 값을 cnt2의 평균 값(반올림해서)으로 대체하라.
결측치가 있는 컬럼에 대해서 처리. 하나의 컬럼이 대상이니 -> series 단위.
rep = round(df['cnt2'].mean(), 2)
df['cnt2'].fillna(rep, inplace = True) # 원본 바꿈.
- fillna() 함수에서 a와 동일한 size의 seires를 넣으면 결측치와 동일한 index명의 값으로 결측치를 채운다.
a = pd.Series([1,2,None, 3,None, 4])
b = pd.Series([100,200,300,400,500, 600])
a.fillna(b)
-----------------
0 1.0
1 2.0
2 300.0
3 3.0
4 500.0
5 4.0
dtype: float64
- 대체를 할 때 전체 대표값 보다는 각 그룹 별 대표값 평균으로 대체
df['cnt2'].fillna(df.groupby('fruits')['cnt2'].transform('mean'), inplace = True)
df각 그룹별로 그룹의 평균 값들이 NaN을 대체할 값으로 넣어주고 싶다.
자신의 그룹에 맞춰, 그룹의 평균값이 들어가야 하므로 transform 을 이용한다.
=> NaN을 가진 데이터 값들은 자신의 그룹의 평균값으로 대체된다.
3. pivot_table()
엑셀의 pivot table 기능을 제공하는 메소드.
: 분류별 집계(Group으로 묶어 집계)를 처리하는 함수로
역할은 groupby() 를 이용한 집계와 같다.
: group으로 묶고자 하는 컬럼을 => 행과 열로 위치시키고 집계값을 값으로 보여준다.
- groupby() 의 경우 다중 그룹화를 할 경우, 해당 그룹을 모두 인덱스명으로 보여준다. 가독성 안 좋음.
** cf) pivot() 함수와 역할이 다르다.
pivot() 은 index와 column의 형태를 바꾸는 reshape 함수.
[ 구문 ]
DataFrame.pivot_table(values=None,
index=None,
columns=None,
aggfunc='mean',
fill_value=None,
margins=False,
dropna=True,
margins_name='All')
- 매개변수
- values
- 문자열 또는 리스트(여러개면). 집계할 대상 컬럼들
- index
- 문자열 또는 리스트(여러개면). index로 올 컬럼들 => groupby였으면 묶었을 컬럼
- columns
- 문자열 또는 리스트(여러개면). column으로 올 컬럼들 => groupby였으면 묶었을 컬럼
(index/columns가 묶여서 groupby에 묶을 컬럼들이 된다.)
- aggfunc
- 집계함수 지정.
함수이름 (문자열), 사용자 정의 함수(객체로)
함수리스트 (여러개면 ), dict: 집계할 함수 (컬럼마다 각각 다르면)
- 기본(생략시): 평균을 구한다. (mean이 기본값)
- fill_value, dropna
- fill_value : 집계시 NA가 나올경우 채울 값
- dropna : boolean(기본: True) 컬럼의 전체값이 NA인 경우 그 컬럼 제거
- margins/margins_name
- 그룹별 집계값 보고 마지막 행마다 총 집계값 보여줌.
- margin : boolean(기본: False) 총집계결과를 만들지 여부.
- margin_name : margin의 이름 문자열로 지정 (생략시 All)
(1) groupby와 pivot_table 차이
# groupby => multi index로 series 나옴.
flights.groupby(['AIRLINE', 'MONTH'])['AIR_TIME'].mean()
- 2차 그룹으로 집계하면 : multi index로 => 가독성이 안 좋다.
이를 행과 열로 나눠 보자. -> 피벗테이블
flights.pivot_table(values = ['AIR_TIME'], # 집계 대상
index = 'AIRLINE', # Grouping 할 대상 컬럼 중 index 로 올 컬럼
columns = 'MONTH', # Grouping 할 대상 컬럼 중 columns 로 올 컬럼
aggfunc = "mean", # 집계 함수
margins = True,
margins_name = "총통계치"
)
(2) NaN 값 대체
- NAN 값은 그 group들의 값을 가진 행이 없는 경우에 나온다.
즉, 첫번째 그룹과 두번째 그룹을 동시에 만족하는 데이터는 없을 때.
- 0 값은 합계를 구했더니 진짜 0인것. 집계할 값이 없는 게 아님.!
- fill_value = "결측치"
flights.pivot_table(values = ['AIR_TIME'], # 집계 대상
index = 'AIRLINE', # Grouping 할 대상 컬럼 중 index 로 올 컬럼
columns = 'MONTH', # Grouping 할 대상 컬럼 중 columns 로 올 컬럼
aggfunc = "mean", # 집계 함수
fill_value = "결측치",
margins = True,
margins_name = "총통계치"
)
(3) 여러 집계값 / 집계대상컬럼 / index/ colums 의 컬럼을 여러 개 넣을 경우 리스트로 묶어서 전달.
flights.pivot_table(values= 'ARR_DELAY',
index = ['AIRLINE','ORG_AIR'],
columns = 'MONTH',
aggfunc = ['min','max'],
margins = True)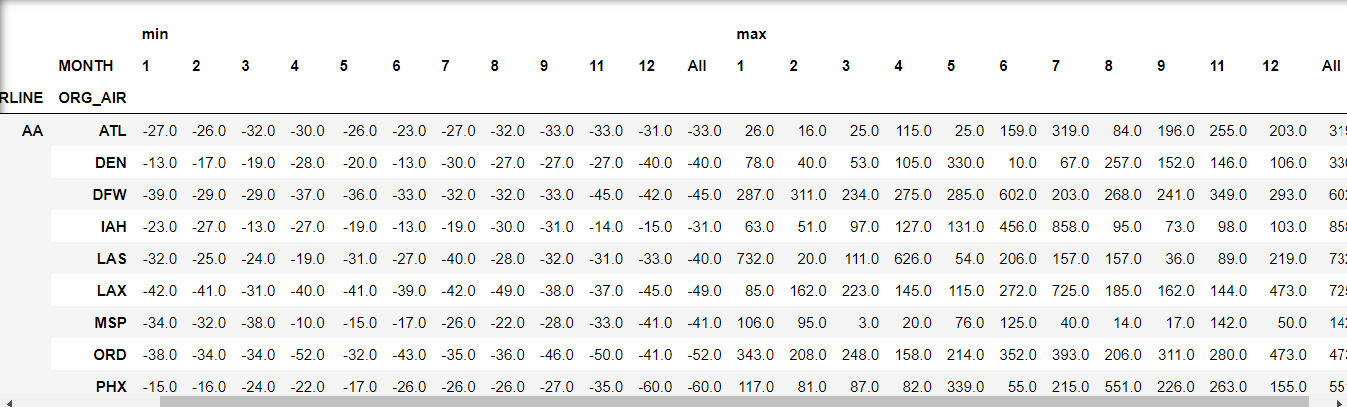
- min 에 대한 총 집계 , max에 대한 총 집계 따로 나옴.
4. apply() - Series, DataFrame의 데이터 일괄 처리
데이터프레임의 행들과 열들 또는 Series의 원소들에 공통된 처리를 할 때
apply 함수를 이용하면 반복문을 사용하지 않고 일괄 처리가 가능하다.
- DataFrame.apply(함수, axis=0, args=())
- 인수로 행이나 열을 받는 함수를 apply 메서드의 인수로 넣으면
데이터프레임의 행이나 열들을 하나씩 함수에 전달한다.
- 매개변수
- 함수: DataFrame의 행들 또는 열들을 전달할 함수
- axis : 0 -행을 전달, 1 - 열을 전달 (기본값 0)
- args: 행/열 이외에 전달할 매개변수를 위치기반(순서대로) 튜플로 전달
- Series.apply(함수, args=())
- 인수로 Series의 원소들을 받는 함수를 apply 메소드의 인수로 넣으면
Series의 원소들을 하나씩 함수로 전달한다.
- 매개변수
- 함수: Series의 원소들을 전달할 함수
- args : 원소 이외에 전달할 매개변수를 위치기반(순서대로) 튜플로 전달
df의 원소 => series -> Seires(df의 한 행 또는 한 열 씩) 넘어가 일괄처리
series의 원소 => value -> 원소 values 별로 넘아가 일괄처리
1) 기본예제
[ 함수 정의 ]
# apply에 전달할 함수 정의
def func(x):
return x**2
[ 함수 호출 ]
매개변수 : x
- datafram.apply() -> Seires(df의 한 행 또는 한 열) 가 전달
- series.apply() -> Series 원소가 전달.
(1) DataFrame.apply() -> Seires(df의 한 행 또는 한 열) 가 전달
df.apply(func) # 열단위로 전달
df.apply(func, axis =1) # axis = 1 : 행단위로 전달


(2) Series.apply() -> Series 원소가 전달.
df['no1'].apply(func)

2) 추가 매개변수가 있는 경우
def func2(x, value):
return x + value
df.apply(func2, value = 100)- axis 매개변수 때문에, 키워드 인자로 작성해주기
3) 람다식으로도 가능
df.apply(lambda x : x*2, axis = 1) # 행단위
5. cut()/qcut() - 연속형(수치)을 범주형으로 변환
: binning 구간화하여 이를 범주형 변수로 사용한다.
- cut() : 나눌 지점을 지정하여, 그 기준으로 구간을 나눠 그룹으로 묶는다.
규칙없이 내가 원하는 지점에서 구간을 나누고 싶을 때
- pd.cut(x, bins,right=True, labels=None)
- 매개변수
- x: 범주형으로 바꿀 대상. 1차원 배열형태(Series, 리스트, ndarray)의 자료구조 (cf. 당연히 df 안됨)
- bins: 범주로 나눌때의 기준값(구간경계)들을 리스트로 묶어서 전달한다.
- right: 구간경계의 오른쪽(True-기본)을 포함할지, 왼쪽(False)을 포함할지 (ex: True : (10, 20], ()-포함안함, []-포함)
- labels: 각 구간(범주)의 label을 리스트로 전달
- 생략하면 범위를 범주명으로 사용한다.
- qcut() : 대상배열의 최대값 ~ 최소값을 지정한 개수의 동등한 size(원소의개수)가 되도록 나눈다.
- n 등분을 지정하면 동일한 원소의 갯수로 N 개의 그룹으로 나눈다.
- 구간의 원소의 갯수를 똑같게 나누고 싶을 때
- pd.qcut(x, q, labels)
- 매개변수
- x: 나눌 대상. 1차원 배열형태의 자료구조
- q: 나눌 개수
- labels: 각 구간(범주)의 label을 리스트로 전달
** pd의 메소드들이다.
(1) cut()
# right = True (dafalut)
pd.cut(ages, bins= [-1,10,30,40,50])
# ages의 각 index의 값이 어느 그룹에 포함되는지를 반환
dtype: category
Categories (4, interval[int64, right]): [(-1, 10] < (10, 30] < (30, 40] < (40, 50]]
- right = T ,F => 괄호 와 대괄호
( ) => 포함 안 한다는 의미 [ ] => 포함 한다는 의미
right = T : ( 기본값 ) 오른쪽 큰쪽을 포함. (오른쪽을 포함하니? )
[(-1, 10] < (10, 30] < (30, 40] < (40, 50]]
= > (10, 30] : 10 미포함 30 포함. 10 < <=30
=> 0 ~ 10, 11~30, 31 ~ 40, 41~50
right = F : 왼쪽 작은쪽을 포함.
[[-1, 10) < [10, 30) < [30, 40) < [40, 50)]
= > [10,30) : 30 포함. 40 미포함 10 <= <30
= > -1~9 , 10~29, 30~39, 40~49
(2) qcut()
n 등분을 지정하면 동일한 원소의 갯수로 N 개의 그룹으로 나눈다.
pd.qcut((ages), 2)
dtype: category
Categories (2, interval[float64, right]): [(0.999, 22.5] < (22.5, 48.0]]
(3) 라벨 붙이기 범주형 타입 데이터 만들기
- 구간 수와 라벨 수 맞게 적기. 오름차순 정렬대로 라벨이 붙는다.
- age_cate 는 범주형 타입의 컬럼 sereis 로 DF 에 붙일 수 있다.
labels = ['19세 이하', '10,20대 ', '30대', '40대']
age_cate = pd.cut(ages, bins=bins, labels = labels)
# 데이터프레임으로 만들기
age_df = pd.DataFrame({'나이':ages, '나이대':age_cate})
age_df
★
(4) 구간화하여 범주값을 가지는 컬럼으로 DF 추가
이거 하려고 배운 것
EX. price 컬럼을 '고가', '중가', '저가' 세개의 범주값을 가지는 "price_cate" 컬럼을 생성하라.
# 구간화하여 범주형 데이터 만들기
price_cate = pd.qcut(dia['price'], 3, labels=["저가", "중가", "고가"])
# DF에 7번째 컬럼 price_cate 라는 이름으로 삽입
dia.insert(7, "price_cate", price_cate)
'AI_STUDY > Pandas' 카테고리의 다른 글
| pandas _ nlargest, nsmallest (0) | 2022.06.22 |
|---|---|
| Pandas _ 06 DataFrame_재구조화 (0) | 2022.06.15 |
| 데이터셋 read시 루틴 (0) | 2022.06.10 |
| Pandas _ 03-2 집계 (0) | 2022.06.09 |
| Pandas _ 03-1 정렬 (0) | 2022.06.09 |

