
ㅅㅇ
Pandas _ 03-2 집계 본문
Pandas_03_2 집계
1. 기술통계메소드들을 이용한 데이터 집계
- DataFrame 에 위의 기술 통계 메소드를 적용할 경우 컬럼별로 계산 -> Series 반환
- sum(), mode(), max(), min(), unique(), nunique(), count()는 문자열에 적용가능
- 문자열에서 mode(), unique(), numique(), count()는 중요하지만,
- sum() 은 문자열 적용 되지만 무쓸모.
- max(), min() 유니코드 기준으로 큰,작은 값 반환한다.
- idxmax(), idxmin() 는 문자열 컬럼에 사용할 수 없다.
- 큰 , 작은 값을 가진 index를 알고 싶다면, numpy 에서 np.argmax(), np.argmin()을 사용한다.
- 기본적으로 결측치(NA)는 제외(없는 행으로)하고 처리한다.
- 결측치 제외하지 않으려면 skipna=False 를 매개변수로 추가.
- 만약, NA 를 포함하여 sum(), mean() 등 연산을 한다면 결과 값도 NA로 나온다.
[주요 기술 통계 메소드]
| sum() | 합계 | - 문자열 가능 |
| mean() | 평균 | |
| median() | 중위수(중앙값) | |
| mode() | 최빈값 | - 문자열 가능 |
| quantile() | 분위수 | 매개변수 q = [ 0.5 ] |
| std() | 표준편차 | |
| var() | 분산 | |
| count() | 결측치를 제외한 원소 개수 (행의 수를 센다) | ** bool 조건에 만족하는 True 행 수 셀 때 얘 사용 안함. => sum() - 문자열 가능 |
| min() | 최소값 | - 문자열 가능 |
| max() | 최대값 | - 문자열 가능 |
| idxmax() | 최대값 index | |
| idxmin() | 최소값 index | |
| unique() | 고유값 | - 문자열 가능 |
| nunique() | 고유값의 개수 | - 문자열 가능 |
| cf) value_counts() | (series만 가능) series의 범주형 데이터 별 갯수를 series로 반환. |
.values_counts(normalize=True) : 비율로 ex ) flights['MONTH'].value_counts() 범주형 컬럼 데이터를 조회한 series에 대해 각 범주 데이터 별 갯수를 count함. - 범주형 컬럼 찾을 때 사용.. |
(1) 범주형 컬럼
- 범주형 데이터 찾기
우린 범주형 데이터를 가진 컬럼을 기준으로 group by 한다.
그렇기에 범주형 컬럼을 찾을 수 있어야 한다. ==> [series].value_counts()
=> 가능성 있는 데이터 타입 : object , int
- object 타입의 컬럼 데이터가 범주형인지 단순 문자열을 뜻하는지 알아야 함.
- int 타입의 컬럼 데이터가 수치적 의미를 갖는지, 범주의 의미를 갖는지 알아야 함.
# 방법1 14개 고유값이면 범주형일 확률이 높다.
flights['AIRLINE'].nunique()
# 방법2 [하나의 컬럼 조회 결과 series].value_counts()
# 컬럼 조회 결과 series 에 대해 각 범주 데이터 별 몇 개 있는지를 알려주는 함수 사용.
flights['AIRLINE'].value_counts() # .sort_index
flights['MONTH'].value_counts()
- 범주형 데이터라면?
int 타입의 컬럼이 범주형 데이터라면, 사실 최대값, 최소값, 평균, 합계 등 수치 통계가 필요없다.
데이터가 정수 형태이지만, 정수의 계산을 위해 사용되는 데이터가 아니기 때문이다.
범주형이라면, 최빈값, 고유값, 고유값의 갯수가 더 중요한 통계값일 듯 하다.
(2) 한 컬럼에 대한, Series에 대한 통계량
# 한 컬럼에 대한 flights['MOMTH'] : Series 에 대한 통계량
flights["MOMTH"] # => Series
flights['MONTH'].max(), flights['MONTH'].min()
flights['MONTH'].mean(), flights['MONTH'].sum(), flights['MONTH'].mode()
(3) DataFrame 에 대한 통계량 : '컬럼별' 통계량을 반환 ( Series )
df.mean()- 데이터 프레임 내 object 데이터가 있다면 이 컬럼을 제외하고 mean() 처리 결과를 반환하는데
이때, 경고메시지가 뜬다.
=> 그렇다면, 통계 처리가 가능한 number 숫자형 데이터만을 조회해서 이들의 평균 구하자.
number : 숫자형 (모든 실수, 정수타입) # include='number' exclude='object'
df.select_dtypes(include = ["number"]).mean()
- 결측치를 포함해서 계산하고 싶을 때
NaN를 포함하여 계산하니 평균 결과가 NaN 나오는 것을 확인할 수 있다.
df.mean(skipna=False)
- (행, 열) = > (axis= 0 , axis = 1)
( default ) axis = 0 컬럼 별 행 데이터 계산
axis = 1 인덱스 별 열 데이터 계산
grade.sum()
korean 345.0
math 420.0
dtype: float64
grade.sum(axis=1)
id
id-1 180.0
id-2 50.0
id-3 160.0
id-4 190.0
dtype: float64
(4) aggregate : 집계 결과를 묶어서 볼 때, 사용자 정의 집계 메소드 사용
aggregate( func, axis = 0, *args, **kwargs )agg(func, axis = 0, *args, **kwargs)- 둘 다 똑같은데 이름만 다른 것. agg 쓰면 된다.
- 목적
- DataFrame, Series의 메소드로 집계결과를 다양한 형태로 묶어서 볼때 사용한다. => 집계 함수를 여러 개 !!!
- 사용자 정의 집계메소드를 사용할 때도 편리하다.
- 매개변수
- func
- 집계 함수 지정
- 하나 : 함수명 / 여러개 : 함수리스트 [ ]
- 판다스 제공 집계메소드들은 문자열로 ( "max" )
- 사용자정의 집계함수는 함수 객체로 전달 ( diff_func )
- 사실 집계함수 하나면 agg 쓸 필요없는데, 사용했다면 사용자정의 집계함수이다.
- 딕션어리 : {'집계할컬럼' : 집계함수, 컬럼: [집계함수, ... ]... }
- 컬럼마다 다른 집계를 할 경우(a컬럼은 합, b컬럼은평균 ...)
- key 컬럼, values 집계함수
- axis
- 데이터프레임이 이차원이니 집계도 두 방향으로 할 수 있다.
- 0 또는 'index' (기본값) : 컬럼 별 집계 (수직 방향으로 계산)
- (행, 열) : 컬럼별로 행 데이터로 집계하니 행 없어지고 각 컬럼에 대한 값으로 결과 나옴
- 각 컬럼에 대한 집계
- 1 또는 'columns' : 행 별 집계 (수평 방향으로 계산)
- 각 행에 대한 집계
- *args, **kwargs
- 함수에 전달할 매개변수.
- 함수 하나일 때만 가능. 리스트에 여러 개 넣은 경우엔 사용할 수 없다.
- 집계함수는 첫번째 매개변수로 Series를 받는다. 그 이외의 매개변수가 있는 경우.
(1) series에 적용
# series에 적용
flights['ARR_DELAY'].agg(["mean", "max", "min"])
# -> series 반환
mean 5.812315
max 1185.000000
min -60.000000
Name: ARR_DELAY, dtype: float64
(2) DataFrame
- 여러개 통계량 : 메소드들을 [] 리스토로 묶어서 전달
- pandas 제공 메소드들 : 문자열 메소드 이름만 제공
flights.select_dtypes(exclude=['object']).agg(['count','mean','std','min', 'max', 'median'])
(3) 매개변수가 필요한 통계 메소드
=> 가변인자
- 하나의 함수에 대해서만 가변인자가 전달할 수 있다.
판다스 제공 메소드로 여러 집계를 한번에 조회하려고 agg를 쓰는데 하나에 대해서라면 굳이 agg 쓸 필요 없다.
그렇기에 이 가변인자는 사용자 정의의 통계함수를 agg를 이요해 사용할 때 적용한다.
flights.agg("quantile", q=[0.25,0.5,0.75])
(4) 컬럼별로 다른 통계량 조회
=> 딕셔너리 {컬럼명 : 통계함수, ... }
flights.agg({"ARR_DELAY":"mean", "DEP_DELAY":["sum", "mean"]})
★ 범주형 컬럼
- 범주형 데이터 찾기
우린 범주형 데이터를 가진 컬럼을 기준으로 group by 한다.
그렇기에 범주형 컬럼을 찾을 수 있어야 한다. ==> [series].value_counts()
=> 가능성 있는 데이터 타입 : object , int
- object 타입의 컬럼 데이터가 범주형인지 단순 문자열을 뜻하는지 알아야 함.
- int 타입의 컬럼 데이터가 수치적 의미를 갖는지, 범주의 의미를 갖는지 알아야 함.
# 방법1 14개 고유값이면 범주형일 확률이 높다.
flights['AIRLINE'].nunique()
# 방법2 [하나의 컬럼 조회 결과 series].value_counts()
# 컬럼 조회 결과 series 에 대해 각 범주 데이터 별 몇 개 있는지를 알려주는 함수 사용.
flights['AIRLINE'].value_counts() # .sort_index
flights['MONTH'].value_counts()
- 범주형 데이터라면?
int 타입의 컬럼이 범주형 데이터라면, 사실 최대값, 최소값, 평균, 합계 등 수치 통계가 필요없다.
데이터가 정수 형태이지만, 정수의 계산을 위해 사용되는 데이터가 아니기 때문이다.
범주형이라면, 최빈값, 고유값, 고유값의 갯수가 더 중요한 통계값일 듯 하다.
2. Groupby
: 특정 열 (범주 데이터) 을 기준으로 데이터셋을 묶는다.
'~~ 별 집계'를 할 때 사용한다.
★
- 구문
DF.groupby('그룹으로묶을기준컬럼')['집계할 컬럼'].집계함수()
- 다중 그룹 groupby에 여러개의 컬럼을 기준으로 나눌 경우 : 리스트에 묶어서 전달한다.
- 집계할 컬럼이 여러개인 경우 : 리스트로 묶어준다. (펜시 조회처럼.)
- 집계함수가 여러개 인 경우 : .agg(['max', 'min' ])
어떤 기준 컬럼(범주형)으로 그룹화하고 어떤 컬럼에 대해 어떻게 집계하여 반환할까?
집계할 컬럼이 1라면 series 반환. 여러 개면 데이터프레임 반환
★
- 집계함수
- 기술통계 함수들
- agg()/aggregate()
- 여러 다른 집계함수 호출시(여러 집계를 같이 볼경우)
- 사용자정의 집계함수 호출시
- 컬럼별로 다른 집계함수들을 호출할 경우 (딕셔너리)
** 어떻게 그룹으로 묶었는지 확인(평소에 쓸 일 없음.)
G.groups #{'AA':[AA인 인덱스명] , ...}
(1) 기본
'AIRLINE 별' (그룹바이하고) '도착딜레이시간' 의 '평균'(원하는 컬럼을 집계)
flights.groupby('AIRLINE')['ARR_DELAY'].mean()
(2) 집계할 컬럼이 여러 개
'AIRLINE 별' '출발, 도착 딜레이 시간' 의 '평균'
flights.groupby('AIRLINE')[['DEP_DELAY', 'ARR_DELAY']].mean()
(3) 집계할 컬럼이 여러개. 집계할 함수 여러 개
' AIRLINE 별' '출발, 도착 딜레이 시간' 의 ' 최소, 최대값 '
| 컬럼 || 이중인덱스 |

flights.groupby('AIRLINE')[['DEP_DELAY', 'ARR_DELAY']].agg(['min', 'max'])
(4) 컬럼별로 다른 통계량 들 조회 -> egg (딕셔너리)
AIRLINE 별 '출발 딜레이- 최소,최대값', '도착 딜레이- 합계, 평균'
flights.groupby('AIRLINE').agg({"DEP_DELAY":["min","max"], "ARR_DELAY":["sum", "mean"]})
(5) 복수열 기준 그룹핑 - 다중 그룹 n차 그룹
- 두개 이상의 열을 그룹으로 묶을 수 있다.
- groupby의 매개변수에 그룹으로 묶을 컬럼들의 이름을 리스트로 전달한다.
'항공사별'의 '월별' '도착 딜레이 시간'의 '평균'
-> 컬럼이 하나라 series. 인덱스가 이중
flights.groupby(['AIRLINE','MONTH'])['ARR_DELAY'].mean()
# multi index : AIRLINE~ MONTH 부분 전체가 INDEX이다.
# 컬럼이 하나라 series로 반환.
INDEX | values |
AIRLINE MONTH
AA 1 9.436282
2 6.262032
3 10.639535
4 1.503628
5 7.549231
...
WN 7 13.458750
8 6.542675
9 -1.232824
11 1.846154
12 8.947575
- Seires 의 multi index 조회할 때는! series 조회 인덱스 자리에 [ 'A', 1 ]
result = flights.groupby(['AIRLINE','MONTH'])['ARR_DELAY'].mean()
# Seires 의 multi index 조회할 때는!
result['AA',1]
EX.) 항공사 별, 요일 별 연착과 취소 횟수는?
- 연착과 취소 데이터의 값을 보면 0과 1로 이뤄져있다. yes 1 no 0.
- count 는 결측치가 아닌 행수! 를 세는 것. count하면 1도 0도 결측치 빼고 행을 다 샌다.
- 1인 것만 세야 한다 -> sum() 해주면 1인 행 갯수를 구할 수 있다
flights.groupby(["AIRLINE","WEEKDAY"])[["DIVERTED", "CANCELLED"]].sum()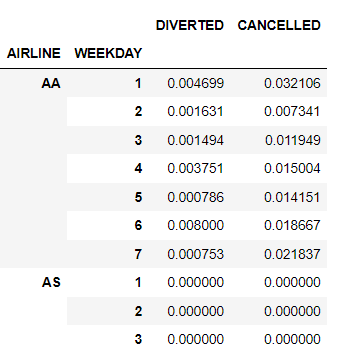
3. SQL having 처럼 집계한 것 중 특정 조건의 항목만 보기
- 따로 함수는 없고, 집계 후 boolean indexing으로 having절 처리해주는 방법 뿐이다.
항공사별 취소 건수 조회에 대한 결과 데이터프레임에 대해 => flights.groupby('AIRLINE')['CANCELLED'].sum()
그 데이터프레임의 각 행(항공사별 취소 건수) 중 100인 이상인 행만 조회. => re[re >= 100] boolean indexing
# 항공사별 취소 건수가 100 건 이상인 결과만 보고싶다.
flights.groupby('AIRLINE')['CANCELLED'].sum()[flights.groupby('AIRLINE')['CANCELLED'].sum() >= 100]
# 복잡. 변수로 뽑아서 하기.
re = flights.groupby('AIRLINE')['CANCELLED'].sum()
re[re >= 100]# cut과 color 별로 가격은 평균을 carat은 최대값을 조회. 가격의 평균이 5000이상이고 carat의 최대값이 3이상인 결과만 조회
re = dia.groupby(["cut","color"]).agg({"price":"mean", "carat":"max"})
re[ (re["price"] >=5000) & (re["carat"].max() >= 3 )]
4. 사용자 정의 집계함수를 만들어 적용
4.1 사용자 정의 집계 함수 정의
- 매개변수
1. Series 또는 DataFrame을 받을 매개변수(필수)
2. 필요한 값을 받을 매개변수를 선언한다. (선택)
4.2 agg() 를 사용해 사용자 정의 집계 함수 호출
(1) DataFrame.agg(func=None, axis=0, *args, **kwargs)
- axis : 사용자 정의 함수에 전달할 값들(Series)의 축 지정.
어떤 방향의 데이터 sereis를 전달할 지
(2) Series.agg(func=None, axis=0, *args, **kwargs)
- DataFrame의 agg와 매개변수 구조를 맞추기 위해 axis 지정한다.
- kwargs를 이용해 매개변수 전달할 경우 axis는 생략해도 된다. - > axis기본값 0 (행)을 그냥 쓰면 되므로.
- keyword 인자 뒤에 position 인자는 안되서 *args로 값 전달시에는 axis를 지정해야 한다.
_그룹화_
(3) DataFrameGroupBy.agg(func, *args, **kwargs) :
- 그룹화된 데이터프레임에 대해서니깐 -> axis 지정안함.
- 사용자 함수에 Series를 group 별로 전달한다.
(4) SeriesGroupBy.agg(func=None, *args, **kwargs)
- 그룹화된 데이터프레임에 대해서니깐 -> axis 지정안함
- 사용자 함수에 Series를 group 별로 전달한다.
- *args, **kwargs는 사용자 정의 함수에 선언한 매개변수가 있을 경우 전달할 값을 전달한다.
- 키워드 인자를 이용해 가변인자로 전달하는 것이 편하다.
- 만들 일 거의 없긴 하다.
ex) 사용자정의 집계함수(통계함수) : 매개변수 없는 사용자 정의 함수
최대값과 최소값의 차이를 구하는 함수 만들기!
[ 함수정의 ]
def max_min_diff(X):
if X.dtypes == "object":
raise TypeError("수치형 타입만 계산할 수 있습니다.") # 예외처리
return X.max() - X.min()
- 매개변수로 Series나 DataFrame 을 받을 변수, 그 외에 필요한 변수를 추가 선언하면된다.
=> X : Series, DataFrame을 받을 변수
- 해당 연산은 수치형 타입의 데이터에 대해서만 처리해야 한다.
=> X가 수치형(int, float)이 아니면 예외발생
[ 함수호출 ]
X 에 들어갈 값은 Series, DataFrame이다.
- 한 컬럼에 대한 (series)
max_min_diff(flights['ARR_DELAY'])
- 사용자 정의 함수와 판다스 제공함수를 함께 집계할 때
- 판다스 제공 함수 : 함수이름은 문자열로 제공.
- 사용자 정의 통계량 함수 : 함수 객체 를 넣어야 함.
# ARR_DELAY 의 최소값, 최대값, 최대값과 최소값의 차이
# 함수 자체를 넣어줘야 함
flights['ARR_DELAY'].agg(['min','max', max_min_diff])
- 그룹바이 한 데이터프레임에서 사용자 정의함수 통계를 할 때
사용자 정의 통계량 함수가 객체 로 들어간다는 것 뿐. 다를 것 없다. 메소드체인 생각해서 쭉 적어주면 됨
flights.groupby(['AIRLINE','MONTH'])[['DEP_DELAY','ARR_DELAY']].agg(['min', 'max', max_min_diff])
flights.groupby(['AIRLINE','MONTH']).agg({'DEP_DELAY':max_min_diff, 'ARR_DELAY':['min','max', max_min_diff]})
'AI_STUDY > Pandas' 카테고리의 다른 글
| Pandas _ 04 groupby 관련메소드 및 일괄처리 메소드 (0) | 2022.06.10 |
|---|---|
| 데이터셋 read시 루틴 (0) | 2022.06.10 |
| Pandas _ 03-1 정렬 (0) | 2022.06.09 |
| Pandas _ 02-4 DataFrame 접근 _ 컬럼/행의 값 조회 및 변경 (0) | 2022.06.08 |
| Pandas _ 02-3 DataFrame 접근 _ 컬럼/행 조회 및 변경 (0) | 2022.06.08 |


