
ㅅㅇ
numpy _ 01_2 배열 생성 본문
numpy _ 01_2 배열 생성
1. 넘파이 배열(ndarray) 이란?
- Numpy에서 제공하는 N 차원 배열 객체
- 같은 타입의 값들만 가질 수 있다.
- 빠르고 메모리를 효율적으로 사용하며 벡터 연산과 브로드 캐스팅 기능을 제공한다.
- 모듈
# pandas와 matplotlib install할 때 같이 깔림.
!pip install numpy# 관례적으로 사용하는 별칭(alias) : np
# pd. plt, sns, np, tensorflow : tf
import numpy as np
2. 데이터 타입 및 관련 속성과 메소드
- 원소들의 데이터 타입
- ndarray 는 같은 타입의 데이터만 모아서 관리한다.
(1) ndarray.dtype
- 배열 생성시 dtype 속성을 이용해 데이터 타입 설정 가능
- ndarray.dtype 속성을 이용해 배열의 데이터 타입을 조회
(2) ndarray.astype(바꿀 데이터타입)
- 데이터타입 변환하는 메소드
- 변환한 새로운 ndarray객체를 반환
- 데이터 타입
문자열과 numpy 모듈에서 제공하는 변수를 통해 지정할 수 있다.

참고) 각 타입에서 메모리 크기를 지정하지 않은 것(int, uint)들을 deprecated 더 이상 사용되지 않음.
** 정수 : 127~128 / +-32000 / +-21억
주로, 정수형 int32 (+-21억) 실수형(floa64)
3. 배열의 상태를 확인하는 속성값들
1) 데이터타입(dtype)
- 넘파이 안 원소들의 데이터 타입 (넘파이 안 데이터는 모두 같은 데이터 타입을 가져야 한다.)
a4.dtype
2) axis별 크기(shape)
- 튜플로 반환 (5, ) (2, 3) (2, 3, 4)
a4.shape
3) Rank수 (차원수 - ndim)
a4.ndim
4) 원소개수(size)
a4.size
5) len()
- 배열의 가장 바깥 쪽 0번 축의 개수를 반환
- 배열에서는 size 조회해야 함. 이거 사용하지 않음.
len(a4))
6) 원소하나에 배정되는 메모리 크기(byte)
a4.itemsize
# int32bit = 4byte
3. 배열 생성 함수
- '배열형태 객체' 가 가진 원소들로 구성된 numpy 배열 생성
- 다차원 배열을 만들 경우, 각 축 별 데이터의 개수가 동일해야 한다.
3.1 array(배열형태 객체 [, dtype])
- 원하는 값들로 구성된 배열을 만들 때 사용.
- 데이터 타입 지정 안 한다면, 데이터에 맞게 기본값으로.
int32 : 정수 기본 타입, float64 : 실수 기본 타입
- 배열형태 객체 (array-like)
- - > 리스트, 튜플, 넘파이배열(ndarray), Series (흔히, index 있는 애들) 을 넣어서 numpy array 로 만들어줌.
1) 1차원 배열 생성 (5, )
# 1차원 배열 생성
a1 = np.array([1,2,3,4,5])
print(a1.shape) # (5,)
print(type(a1))
print(a1)
print(a1.dtype)
[1 2 3 4 5]
<class 'numpy.ndarray'>
(5,)
int32
2) 2차원 배열 생성 (5,1)
- 0번축 : 원소 5개, 1번축 : 원소 1개
- 데이터 타입 지정 안 해서 정수에 맞춰 int32
a2 = np.array([[1],
[2],
[3],
[4],
[5]])
print(a2.shape)
print(a2.dtype)
print(a2
(5, 1)
int32
[[1]
[2]
[3]
[4]
[5]]
3) 3차원 3darray (2, 4, 3)
l1 = [
[1,2,3],
[4,5,6],
[7,8,9],
[10,11,12]
]
l2 = [
[10,20,30],
[40,50,60],
[70,80,90],
[100,110,120]
]
l3 = [l1,l2]
a3 = np.array(l3)
print(a3.shape)
print(a3.dtype)
print(a3.size)(2, 4, 3)
int32
24
4) 배열 생성 _ 데이터 타입 지정
- 매개변수 dtype =
a4 = np.array(l3, dtype=np.float32)
5) 타입 변환
- 타입을 변환한 새로운 배열을 생성해서 반환. 원본 안 바뀜
a5 = a4.astype('int32')
a5.dtypedtype('int32')
<원하는 배열 형태에 특정 숫자로 채워진 배열 : zeros, ones, full, XXX_like >
3.2 zeros(shape, dtype)
영벡터 생성 : 모든 원소들을 0으로 채운 배열
- shape : 형태(크기, 개수) 지정 - tuple로 지정
- dtype : 배열의 타입을 지정
- 배열의 형태(크기, 개수)를 tuple로 지정
- 모든 원소가 0인 배열의 형태 (2, 3)
- 기본이 float64 이다.
z1 = np.zeros((2,3))
z1array([[0., 0., 0.],
[0., 0., 0.]])
- 1차원 배열 : 튜플로 안 하고 정수로 지정 가능.
z = np.zeros(shape=7, dtype = 'int16')array([0, 0, 0, 0, 0, 0, 0], dtype=int16)3.3 ones(shape, dtype)
- shape : 형태(크기, 개수) 지정
- dtype : 배열의 타입을 지정
- 기본이 float63 데이터 타입
o1 = np.ones(shape=5)
o1array([1., 1., 1., 1., 1.])
- 2차원 배열 (5, 3)
o2 = np.ones(shape=(5,3), dtype='int32')
o2array([[1, 1, 1],
[1, 1, 1],
[1, 1, 1],
[1, 1, 1],
[1, 1, 1]])
3.4 full(shape, fill_value, dtype))
원소들을 원하는 값으로 채운 배열 생성
- shape : 형태(크기, 개수) 지정
- fill_vlaue : 채울 값
- dtype : 배열의 타입을 지정
- 1차원 배열에 정수 10으로 채우기
f1 = np.full(shape=5, fill_value=10)
print(f1.shape)
f1(5,)
array([10, 10, 10, 10, 10])
f2 = np.full(shape=(5,4,3,2), fill_value=1.5)
print(f2.shape)
print(f2.dtype)(5, 4, 3, 2)
float64
3.5 numpy.XXX_like(ndarray)
- shape은 매개변수로 받은 배열의 shape에 XXX로 원소들을 채운다.
- XXX : zeros, ones, full
- zero_like(), ones_like(), full_like()
# shape = (2, 2) 배열 형태
a = np.array([[1,2,],[4,5]])
# a 와 동일한 shape의 0을 원소로 가지는 배열
z = np.zeros_like(a)
# a 와 동일한 shape의 1을 원소로 가지는 배열
o = np.ones_like(a)
# a 와 동일한 shape의 fill_value 로 지정한 100을 원소로 가지는 배열
f = np.full_like(a, 100)[[0 0]
[0 0]]
[[1 1]
[1 1]]
[[100 100]
[100 100]]
< 범위를 지정해 생성하는 배열 : arange, linspace >
3.6 arange(start, stop, step, dtype)
start에서 stop 범위에서 step의 일정한 간격의 값들로 구성된 배열 리턴
= > 1차원 배열(벡터)만 생성
- start : 범위의 시작값으로 포함된다.(생략가능 - 기본값:0)
- stop : 범위의 끝값으로 포함되지 않는다. (필수)
- step : 간격 (기본값 1)
- 증감치 실수도 가능. range와 달리 다양한 형태가 가능해짐
- dtype : 요소의 타입
- 기본예제
# start, stop (step : 1 생략)
np.arange(1,10)
# stop (start:0, step:1 생략)
np.arange(10)
# reverse
np.arange(10,1,-1)array([1, 2, 3, 4, 5, 6, 7, 8, 9])
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
array([10, 9, 8, 7, 6, 5, 4, 3, 2])- 실수 형태도 가능 (python range와 달리)
np.arange(0, 1.1, 0.1) # 1.1 미포함array([0. , 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1. ])
- 자주 쓰인다. 특히나, reshape와 함께
arange와 만든 원소의 size와 reshape로 지정한 배열 구조의 size가 같아야 한다. 아니면 error
cf ) np.arange(1, 13).reshape(2, 4) -- > error
np.arange(1,13).reshape(3,4)
# 1~12 값이 shape (3,4)에 맞춰 순서대로 들어간다.
array([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
3.6 linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
시작과 끝 을 균등하게 나눈 값들을 가지는 배열을 생성
= > 1차원 배열(벡터)만 생성
- start : 시작값
- stop : 종료값
- num : 나눌 개수. 양수 여야한다. def = 50
- endpoint : stop을 포함시킬 것인지 여부. def = True
- retstep : 생성된 배열 샘플과 함께 간격(step) 도 리턴할지 여부. def = False
True일경우 간격도 리턴(sample, step) => 튜플로 받는다.
- dtype : 데이터 타입 def = float64
1) 1 ~ 10 을 동일한 간격으로 나눠 10개. endpoint 포함
a = np.linspace(1,10,10)array([ 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.])stop 인 10은 제외.
b = np.linspace(1,10,10, endpoint = False)array([1. , 1.9, 2.8, 3.7, 4.6, 5.5, 6.4, 7.3, 8.2, 9.1])3) restep = True : (생성된 배열, step 값) 튜플로 반환
b = np.linspace(1,10, 3, retstep=True)(array([ 1. , 5.5, 10. ]), 4.5)
4) 활용 예제 : f(x) 함수 그래프 그리기
- 이때 값 넣을 때 linspace 많이 그림.
x에 값을 넣을 때 범위를 주고 세분화해서 넣기 위해.
import matplotlib.pyplot as plt
def f(x):
return x**2 + 2*x + 3 # 이차함수
x = np.linspace(-3,3,100) # 값을 세분화해서 넣어야 한다.
y = f(x)
plt.plot(x,y)
plt.show()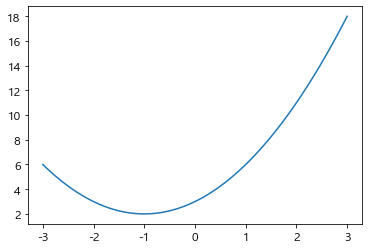
< 난수 random value를 원소로 하는 ndarray 생성 : rand, random, normal, randint, choice >
3. 7 시드값이란?
- 시드값을 설정하면 항상 일정한 순서의 난수(random value)가 발생한다.
random value 랜덤함수이란 ?
- 시작 숫자는 실행할때 마다 바뀌므로 다른 값들이 나오는데
- 매번 실행할때 마다 같은 순서의 임의의 값이(난수) 나오도록 할때 시드값을 설정한다.
- 왜 seed 값을 설정하는지, 어떤 역할을 하는지 이해하자.
왜 머신러닝에서 seed 값 고정 설정할까?
머신러닝 할 때 알고리즘과 난수 두 가지를 고려해야 한다.
성능 개선을 위해 둘을 조정할 수 있는데, 난수는 고정시키고 알고리즘을 개선해야 한다.
이때 난수를 고정시키기 위해, 항상 일정한 난수가 나오도록 seed 값을 고정 설정하는 것이다.
3.8 np.random.rand(axis0[, axis1, axis2, ...])
- 0 ~ 1사이의 실수를 리턴
- 축의 크기는 순서대로 나열한다.
axis0의 원소의 개수, axis1의 원소의 개수, axis3의 원소의 개수 ...
- 기본값 0 ~ 1 중 값 1개 (scalar)
np.random.rand()0.502017227692706
- axis 0 축에 0 ~ 1 중 값 1 개 (1차원 배열)
np.random.rand(1)array([0.34367645])- 균등 분포 (각각의 값이 나올 확률이 동일 ) 을 따른다.
그래프를 보면, 각 고유값의 개수가 1개, 랜덤하게 나온 값이 한번씩 나왔다는 걸 알 수 있다.
== > 10000개가 나올 확률이 동일하다는 것을 알 수 있다.
# r.shape = (10000,)
r = np.random.rand(10000)
x, y = np.unique(r, return_counts = True)
# (고유값:nadarray, 각 고유값의 개수: ndarray) 튜플로반환plt.bar(x, y )
plt.show()
- 3차원 배열 구조에 0 ~ 1 사이의 원소가 들어감.
# shape (3,2,2) 생성
r = np.random.rand(3,2,2)array([[[0.70708716, 0.53746457],
[0.02460475, 0.65945077]],
[[0.8931828 , 0.22407895],
[0.65951269, 0.63453096]],
[[0.80365327, 0.9947151 ],
[0.03168634, 0.48021401]]])
3.8 np.random.random(axis0[, axis1, axis2, ...])
- rand와 동일한 함수
- rand 와 차이는 shape를 튜플로 묶어서 전달.
- 0 ~ 1사이의 실수를 리턴
r = np.random.random((3,2,2))array([[[0.02506642, 0.95469143],
[0.89071855, 0.5395372 ]],
[[0.58446729, 0.61604735],
[0.30741446, 0.6184266 ]],
[[0.77513932, 0.94336509],
[0.08373141, 0.00386124]]])
3.9 np.random.normal(loc=0.0, scale=1.0, size=None)
정규분포를 따르는 난수.
- 랜덤하게 뽑고 싶은데 특정 구간에 많이 나왔으면 좋겠다.
이때, normal 평균과 표준편차를 설정하면 됨.
- loc: 평균
- scale: 표준편차
- size : 원소의 갯수
- loc, scale 생략시 표준정규 분포를 따르는 난수를 제공
> 표준정규분포
> 평균 : 0, 표준편차 : 1 인 분포
- 평균에서 +-1 표준편차 구간에 전체의 68%
+-2 표준편차 구간에 전체 중 95%
+-3 표준편차 구간에 전체중 99%가 있다. (나올 확률)
ex ) 평균:10, 표준편차:3
- 1표준편차구간: 7~13 ( 10-3 ~ 10+3 ) 이 나올 확률이 68%
- 2표준편차구간: 4~16 ( 10-6 ~ 10+6 ) 이 나올 확률이 95%
- 3표준편차구간: 1~19 ( 10-9 ~ 10+9 ) 이 나올 확률이 99%
- 기본예제 : 8~12 : 95% 대부분 이 구간 내 숫자가 나옴.
r = np.random.normal(loc=10, scale=1, size=100)
r.max(), r.min()(12.201154320858304, 7.186139861304305)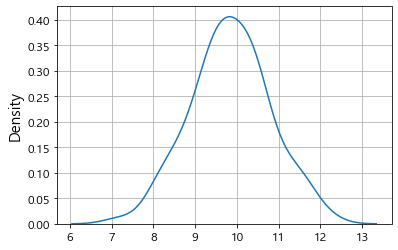
3.10 np.random.randint ( low, high=None, size=None, dtype='int32')
지정한 범위 내 임의의 정수를 가지는 배열
- low(시작) ~ high(끝 - 1) 사이의 정수 리턴. high는 포함 안 됨
- high 생략시 0 ~ low 사이 정수 리턴. low는 포함안됨
- size : 배열의 크기. shape 지정. (안 하면 기본 스칼라 1개 나온다.)
1차원 : 정수
다차원 : 튜플
- dtype : 원소의 타입
# 1 ~ 10-1 임의의 정수를 반환
np.random.randint(1,10)
# 0 ~ 2-1 임의의 정수
np.random.randint(2)
# 1 ~ 9 임의의 정수. (20, )
r = np.random.randint(1,10, size=20)
# 1 ~ 9 임의의 정수. (5, 4)
r = np.random.randint(1,10, size=(5,4))# 마지막 줄 결과. 1 ~ 9 사이에 무작위로 원소 들어감.
array([[9, 4, 8, 4],
[6, 2, 3, 2],
[3, 5, 8, 6],
[8, 5, 3, 9],
[7, 9, 8, 4]])
3.11 np.random.choice(a, size=None, replace=True, p=None)
샘플링 메소드 : 샘플링 대상 a 의 원소들 중 지정한 shape에 맞춰 임의의 원소가 추출됨.
- a : 샘플링대상.
1차원 배열 또는 정수 (정수일 경우 0 ~ 정수, 정수 불포함)
- size : shpae 지정. 무조건 해야 함.(안 한다고 스칼라 나오는 거 아님.)
-- > 배열을 반환하는 함수.!
1차원 : 정수
다차원 : 튜플
- replace : True-복원추출(기본), False-비복원추출
- p: 샘플링할 대상 값들이 추출될 확률 지정한 배열
1) 복원 추출 : 중복된 값이 나올 수 있다. 무한대로 뽑을 수 있다.
- 1, 2, 3, 4, 5 원소 중, (2, ) 배열 구조로 뽑아라.
np.random.choice([1,2,3,4,5], size = 2)# (1, 1) 이렇게 나올 수 있다. : 1 뽑고 다시 1를복원해서
array([1, 1])
2) 비복원 추출 : 중복된 값이 나올 수 없다.
- 1,2,3 원소 중, (4, ) 배열 구조로 뽑아라.
- > 지정한 원소 3개. : 최대 size는 배열의 원소수 3번 뽑을 수 있다.
np.random.choice([1,2,3], size = 4, replace=False)
- > 비복원 추출 error.
3) 1차원 배열 구조 : 정수로
다차원 배열 구조 : tuple로 묶어야 한다.
r = np.random.choice([1,2,3], size=(5,4))array([[3, 1, 2, 3],
[2, 1, 2, 1],
[2, 1, 1, 3],
[2, 1, 1, 1],
[2, 2, 1, 3]])
4) def : p = None 모든 원소가 동일한 확률 거의 비슷하다.
5) p 설정
sampling 할 때 True는 0.1확률, False는 0.9 확률로 나오도록 처리.
-- > 순서는 뭐 random 하겠지만, 뽑히는 확률이 그러한 것.
# 모집단:[True, False], p =[0.1, 0.9]
r = np.random.choice([True,False], size=100000, p=[0.1,0.9])# np.unique(배열) :원소의 고유값들을 반환. return_counts = True :개수
np.unique(r, return_counts=True)(array([False, True]), array([89883, 10117], dtype=int64))< 순서 바꾸기 : shuffle , permutation >
3.12 shuffle()
: 배열 자체의 순서를 바꾼다. (원본을 바뀜.)
np.random.shuffle(arr)
- 다차원 배열의 경우 0번 축을 기준으로만 섞는다.
# 다차원(2차원 이상)일 경우 0축의 원소들만 섞는다.
# 축 지정도 없음.
> 기존
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
> 결과 : 0 축의 원소들만 섞어짐.
array([[ 0, 1, 2, 3],
[ 8, 9, 10, 11],
[ 4, 5, 6, 7]])
3.13 permutation()
: 순서를 바꾼 배열을 반환한다. (원본 안 바뀜. 카피본)
np.random.permutation(arr)
- 다차원 배열의 경우 0번 축을 기준으로만 섞는다.
# 다차원(2차원 이상)일 경우 0축의 원소들만 섞는다.
# 축 지정도 없음.
> 기존
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])> 결과 : 0 축의 원소들만 섞어짐.
array([[ 0, 1, 2, 3],
[ 8, 9, 10, 11],
[ 4, 5, 6, 7]])
'AI_STUDY > Numpy' 카테고리의 다른 글
| numpy _ 04_2 범용함수(Ufunc, Universal function) (0) | 2022.06.24 |
|---|---|
| numpy _ 04_1 벡터 연산 (0) | 2022.06.24 |
| numpy _ 02_2 정렬 (0) | 2022.06.24 |
| numpy _ 02_1 배열의 원소 조회 (0) | 2022.06.24 |
| numpy _ 01_1 개요 (0) | 2022.06.21 |

